Numerical integration is a standard topic in first-semester calculus. From time to time, I have received questions from students on various aspects of this topic, including:
Why is numerical integration necessary in the first place?
Where do these formulas come from (especially Simpson’s Rule)?
How can I do all of these formulas quickly?
Is there a reason why the Midpoint Rule is better than the Trapezoid Rule?
Is there a reason why both the Midpoint Rule and the Trapezoid Rule converge quadratically?
Is there a reason why Simpson’s Rule converges like the fourth power of the number of subintervals?
In this series, I hope to answer these questions. While these are standard questions in a introductory college course in numerical analysis, and full and rigorous proofs can be found on Wikipedia and Mathworld, I will approach these questions from the point of view of a bright student who is currently enrolled in calculus and hasn’t yet taken real analysis or numerical analysis.
In this series, we have shown the following approximations of errors when using various numerical approximations for . We obtained these approximations using only techniques within the reach of a talented high school student who has mastered Precalculus — especially the Binomial Theorem — and elementary techniques of integration.
As we now present, the formulas that we derived are (of course) easily connected to known theorems for the convergence of these techniques. These proofs, however, require some fairly advanced techniques from calculus. So, while the formulas derived in this series of posts only apply to (and, by an easy extension, any polynomial), the formulas that we do obtain easily foreshadow the actual formulas found on Wikipedia or Mathworld or calculus textbooks, thus (hopefully) taking some of the mystery out of these formulas.
Numerical integration is a standard topic in first-semester calculus. From time to time, I have received questions from students on various aspects of this topic, including:
Why is numerical integration necessary in the first place?
Where do these formulas come from (especially Simpson’s Rule)?
How can I do all of these formulas quickly?
Is there a reason why the Midpoint Rule is better than the Trapezoid Rule?
Is there a reason why both the Midpoint Rule and the Trapezoid Rule converge quadratically?
Is there a reason why Simpson’s Rule converges like the fourth power of the number of subintervals?
In this series, I hope to answer these questions. While these are standard questions in a introductory college course in numerical analysis, and full and rigorous proofs can be found on Wikipedia and Mathworld, I will approach these questions from the point of view of a bright student who is currently enrolled in calculus and hasn’t yet taken real analysis or numerical analysis.
In this previous post in this series, we showed that the Simpson’s Rule approximation of has an error of
.
In this post, we consider the global error when integrating on the interval instead of a subinterval .
The total error when approximating will be the sum of the errors for the integrals over , , through . Therefore, the total error will be
So that this formula doesn’t appear completely mystical, this actually matches the numerical observations that we made earlier. The figure below shows the left-endpoint approximations to for different numbers of subintervals. If we take and , then the error should be approximately equal to
,
which, as expected, is close to the observed error of .
Let , so that the error becomes
,
where is the average of the . (We notice that there are only terms in this sum since we’re adding only the even terms.) Clearly, this average is somewhere between the smallest and the largest of the . Since is a continuous function, that means that there must be some value of between and — and therefore between and — so that by the Intermediate Value Theorem. We conclude that the error can be written as
,
Finally, since is the length of one subinterval, we see that is the total length of the interval . Therefore,
,
where the constant is determined by , , and . In other words, for the special case , we have established that the error from Simpson’s Rule is approximately quartic in — without resorting to the generalized mean-value theorem and confirming the numerical observations we made earlier.
Numerical integration is a standard topic in first-semester calculus. From time to time, I have received questions from students on various aspects of this topic, including:
Why is numerical integration necessary in the first place?
Where do these formulas come from (especially Simpson’s Rule)?
How can I do all of these formulas quickly?
Is there a reason why the Midpoint Rule is better than the Trapezoid Rule?
Is there a reason why both the Midpoint Rule and the Trapezoid Rule converge quadratically?
Is there a reason why Simpson’s Rule converges like the fourth power of the number of subintervals?
In this series, I hope to answer these questions. While these are standard questions in a introductory college course in numerical analysis, and full and rigorous proofs can be found on Wikipedia and Mathworld, I will approach these questions from the point of view of a bright student who is currently enrolled in calculus and hasn’t yet taken real analysis or numerical analysis.
In this post, we will perform an error analysis for Simpson’s Rule
where is the number of subintervals (which has to be even) and is the width of each subinterval, so that .
As noted above, a true exploration of error analysis requires the generalized mean-value theorem, which perhaps a bit much for a talented high school student learning about this technique for the first time. That said, the ideas behind the proof are accessible to high school students, using only ideas from the secondary curriculum (especially the Binomial Theorem), if we restrict our attention to the special case , where is a positive integer.
For this special case, the true area under the curve on the subinterval will be
In the above, the shorthand can be formally defined, but here we’ll just take it to mean “terms that have a factor of or higher that we’re too lazy to write out.” Since is supposed to be a small number, these terms will small in magnitude and thus can be safely ignored.
Earlier in this series, we derived the very convenient relationship relating the approximations from Simpson’s Rule, the Midpoint Rule, and the Trapezoid Rule. We now exploit this relationship to approximate . Earlier in this series, we found the Midpoint Rule approximation on this subinterval to be
while we found the Trapezoid Rule approximation to be
.
Therefore, if there are subintervals, the Simpson’s Rule approximation of — that is, the area under the parabola that passes through , , and — will be . Since
,
,
and
,
we see that
.
We notice that something wonderful just happened: the first four terms of perfectly match the first four terms of the exact value of the integral! Subtracting from the actual integral, the error in this approximation will be equal to
Before moving on, there’s one minor bookkeeping issue to deal with. We note that this is the error for , where subintervals are used. However, the value of in this equal arose from and , where only subintervals are used. So let’s write the error with subintervals as
,
where is the width of all of the subintervals. By analogy, we see that the error for subintervals will be
.
But even after adjusting for this constant, we see that this local error behaves like , a vast improvement over both the Midpoint Rule and the Trapezoid Rule. This illustrates a general principle of numerical analysis: given two algorithms that are , an improved algorithm can typically be made by taking some linear combination of the two algorithms. Usually, the improvement will be to ; however, in this example, we magically obtained an improvement to .
Numerical integration is a standard topic in first-semester calculus. From time to time, I have received questions from students on various aspects of this topic, including:
Why is numerical integration necessary in the first place?
Where do these formulas come from (especially Simpson’s Rule)?
How can I do all of these formulas quickly?
Is there a reason why the Midpoint Rule is better than the Trapezoid Rule?
Is there a reason why both the Midpoint Rule and the Trapezoid Rule converge quadratically?
Is there a reason why Simpson’s Rule converges like the fourth power of the number of subintervals?
In this series, I hope to answer these questions. While these are standard questions in a introductory college course in numerical analysis, and full and rigorous proofs can be found on Wikipedia and Mathworld, I will approach these questions from the point of view of a bright student who is currently enrolled in calculus and hasn’t yet taken real analysis or numerical analysis.
In the previous post, we showed that the Trapezoid Rule approximation of has error
In this post, we consider the global error when integrating on the interval instead of a subinterval . The logic is almost a perfect copy-and-paste from the analysis used for the Midpoint Rule.
The total error when approximating will be the sum of the errors for the integrals over , , through . Therefore, the total error will be
.
So that this formula doesn’t appear completely mystical, this actually matches the numerical observations that we made earlier. The figure below shows the left-endpoint approximations to for different numbers of subintervals. If we take and , then the error should be approximately equal to
,
which, as expected, is close to the actual error of .
Let , so that the error becomes
,
where is the average of the . Clearly, this average is somewhere between the smallest and the largest of the . Since is a continuous function, that means that there must be some value of between and — and therefore between and — so that by the Intermediate Value Theorem. We conclude that the error can be written as
,
Finally, since is the length of one subinterval, we see that is the total length of the interval . Therefore,
,
where the constant is determined by , , and . In other words, for the special case , we have established that the error from the Trapezoid Rule is approximately quadratic in — without resorting to the generalized mean-value theorem and confirming the numerical observations we made earlier.
Numerical integration is a standard topic in first-semester calculus. From time to time, I have received questions from students on various aspects of this topic, including:
Why is numerical integration necessary in the first place?
Where do these formulas come from (especially Simpson’s Rule)?
How can I do all of these formulas quickly?
Is there a reason why the Midpoint Rule is better than the Trapezoid Rule?
Is there a reason why both the Midpoint Rule and the Trapezoid Rule converge quadratically?
Is there a reason why Simpson’s Rule converges like the fourth power of the number of subintervals?
In this series, I hope to answer these questions. While these are standard questions in a introductory college course in numerical analysis, and full and rigorous proofs can be found on Wikipedia and Mathworld, I will approach these questions from the point of view of a bright student who is currently enrolled in calculus and hasn’t yet taken real analysis or numerical analysis.
In this post, we will perform an error analysis for the Trapezoid Rule
where is the number of subintervals and is the width of each subinterval, so that .
As noted above, a true exploration of error analysis requires the generalized mean-value theorem, which perhaps a bit much for a talented high school student learning about this technique for the first time. That said, the ideas behind the proof are accessible to high school students, using only ideas from the secondary curriculum (especially the Binomial Theorem), if we restrict our attention to the special case , where is a positive integer.
For this special case, the true area under the curve on the subinterval will be
In the above, the shorthand can be formally defined, but here we’ll just take it to mean “terms that have a factor of or higher that we’re too lazy to write out.” Since is supposed to be a small number, these terms will small in magnitude and thus can be safely ignored.
I wrote the above formula to include terms up to and including because I’ll need this later in this series of posts. For now, looking only at the Trapezoid Rule, it will suffice to write this integral as
.
Using the Trapezoid Rule, we approximate as , using the width and the bases and of the trapezoid. Using the Binomial Theorem, this expands as
Once again, this is a little bit overkill for the present purposes, but we’ll need this formula later in this series of posts. Truncating somewhat earlier, we find that the Trapezoid Rule for this subinterval gives
Subtracting from the actual integral, the error in this approximation will be equal to
In other words, like the Midpoint Rule, both of the first two terms and cancel perfectly, leaving us with a local error on the order of .
We also recall, from the previous post in this series that the local error from the Midpoint Rule was . In other words, while both the Midpoint Rule and Trapezoid Rule have local errors on the order of , we expect the error in the Midpoint Rule to be about half of the error from the Trapezoid Rule.
Numerical integration is a standard topic in first-semester calculus. From time to time, I have received questions from students on various aspects of this topic, including:
Why is numerical integration necessary in the first place?
Where do these formulas come from (especially Simpson’s Rule)?
How can I do all of these formulas quickly?
Is there a reason why the Midpoint Rule is better than the Trapezoid Rule?
Is there a reason why both the Midpoint Rule and the Trapezoid Rule converge quadratically?
Is there a reason why Simpson’s Rule converges like the fourth power of the number of subintervals?
In this series, I hope to answer these questions. While these are standard questions in a introductory college course in numerical analysis, and full and rigorous proofs can be found on Wikipedia and Mathworld, I will approach these questions from the point of view of a bright student who is currently enrolled in calculus and hasn’t yet taken real analysis or numerical analysis.
In the previous post, we showed that the midpoint approximation of has error
In this post, we consider the global error when integrating on the interval instead of a subinterval . The logic for determining the global error is much the same as what we used earlier for the left-endpoint rule.
The total error when approximating will be the sum of the errors for the integrals over , , through . Therefore, the total error will be
.
So that this formula doesn’t appear completely mystical, this actually matches the numerical observations that we made earlier. The figure below shows the left-endpoint approximations to for different numbers of subintervals. If we take and , then the error should be approximately equal to
,
which, as expected, is close to the actual error of .
Let , so that the error becomes
,
where is the average of the . Clearly, this average is somewhere between the smallest and the largest of the . Since is a continuous function, that means that there must be some value of between and — and therefore between and — so that by the Intermediate Value Theorem. We conclude that the error can be written as
,
Finally, since is the length of one subinterval, we see that is the total length of the interval . Therefore,
,
where the constant is determined by , , and . In other words, for the special case , we have established that the error from the Midpoint Rule is approximately quadratic in — without resorting to the generalized mean-value theorem and confirming the numerical observations we made earlier.
Numerical integration is a standard topic in first-semester calculus. From time to time, I have received questions from students on various aspects of this topic, including:
Why is numerical integration necessary in the first place?
Where do these formulas come from (especially Simpson’s Rule)?
How can I do all of these formulas quickly?
Is there a reason why the Midpoint Rule is better than the Trapezoid Rule?
Is there a reason why both the Midpoint Rule and the Trapezoid Rule converge quadratically?
Is there a reason why Simpson’s Rule converges like the fourth power of the number of subintervals?
In this series, I hope to answer these questions. While these are standard questions in a introductory college course in numerical analysis, and full and rigorous proofs can be found on Wikipedia and Mathworld, I will approach these questions from the point of view of a bright student who is currently enrolled in calculus and hasn’t yet taken real analysis or numerical analysis.
In this post, we will perform an error analysis for the Midpoint Rule
where is the number of subintervals and is the width of each subinterval, so that . Also, is the midpoint of the th subinterval.
As noted above, a true exploration of error analysis requires the generalized mean-value theorem, which perhaps a bit much for a talented high school student learning about this technique for the first time. That said, the ideas behind the proof are accessible to high school students, using only ideas from the secondary curriculum (especially the Binomial Theorem), if we restrict our attention to the special case , where is a positive integer.
For this special case, the true area under the curve on the subinterval will be
In the above, the shorthand can be formally defined, but here we’ll just take it to mean “terms that have a factor of or higher that we’re too lazy to write out.” Since is supposed to be a small number, these terms will small in magnitude and thus can be safely ignored.
I wrote the above formula to include terms up to and including because I’ll need this later in this series of posts. For now, looking only at the Midpoint Rule, it will suffice to write this integral as
.
Using the midpoint of the subinterval, the left-endpoint approximation of is . Using the Binomial Theorem, this expands as
Once again, this is a little bit overkill for the present purposes, but we’ll need this formula later in this series of posts. Truncating somewhat earlier, we find that the Midpoint Rule for this subinterval gives
Subtracting from the actual integral, the error in this approximation will be equal to
In other words, unlike the left-endpoint and right-endpoint approximations, both of the first two terms and cancel perfectly, leaving us with a local error on the order of .
The logic for determining the global error is much the same as what we used earlier for the left-endpoint rule.
The total error when approximating will be the sum of the errors for the integrals over , , through . Therefore, the total error will be
.
So that this formula doesn’t appear completely mystical, this actually matches the numerical observations that we made earlier. The figure below shows the left-endpoint approximations to for different numbers of subintervals. If we take and , then the error should be approximately equal to
,
which, as expected, is close to the actual error of .
Let , so that the error becomes
,
where is the average of the . Clearly, this average is somewhere between the smallest and the largest of the . Since is a continuous function, that means that there must be some value of between and — and therefore between and — so that by the Intermediate Value Theorem. We conclude that the error can be written as
,
Finally, since is the length of one subinterval, we see that is the total length of the interval . Therefore,
,
where the constant is determined by , , and . In other words, for the special case , we have established that the error from the Midpoint Rule is approximately quadratic in — without resorting to the generalized mean-value theorem and confirming the numerical observations we made earlier.
Numerical integration is a standard topic in first-semester calculus. From time to time, I have received questions from students on various aspects of this topic, including:
Why is numerical integration necessary in the first place?
Where do these formulas come from (especially Simpson’s Rule)?
How can I do all of these formulas quickly?
Is there a reason why the Midpoint Rule is better than the Trapezoid Rule?
Is there a reason why both the Midpoint Rule and the Trapezoid Rule converge quadratically?
Is there a reason why Simpson’s Rule converges like the fourth power of the number of subintervals?
In this series, I hope to answer these questions. While these are standard questions in a introductory college course in numerical analysis, and full and rigorous proofs can be found on Wikipedia and Mathworld, I will approach these questions from the point of view of a bright student who is currently enrolled in calculus and hasn’t yet taken real analysis or numerical analysis.
In the previous post in this series, we found that the local error of the left endpoint approximation to was equal to
.
We now consider the global error when integrating over the interval and not just a particular subinterval.
The total error when approximating will be the sum of the errors for the integrals over , , through . Therefore, the total error will be
.
So that this formula doesn’t appear completely mystical, this actually matches the numerical observations that we made earlier. The figure below shows the left-endpoint approximations to for different numbers of subintervals. If we take and , then the error should be approximately equal to
,
which, as expected, is close to the actual error of .
We now perform a more detailed analysis of the global error. Let , so that the error becomes
,
where is the average of the . Clearly, this average is somewhere between the smallest and the largest of the . Since is a continuous function, that means that there must be some value of between and — and therefore between and — so that by the Intermediate Value Theorem. We conclude that the error can be written as
,
Finally, since is the length of one subinterval, we see that is the total length of the interval . Therefore,
,
where the constant is determined by , , and . In other words, for the special case , we have established that the error from the left-endpoint rule is approximately linear in — without resorting to the generalized mean-value theorem.
Numerical integration is a standard topic in first-semester calculus. From time to time, I have received questions from students on various aspects of this topic, including:
Why is numerical integration necessary in the first place?
Where do these formulas come from (especially Simpson’s Rule)?
How can I do all of these formulas quickly?
Is there a reason why the Midpoint Rule is better than the Trapezoid Rule?
Is there a reason why both the Midpoint Rule and the Trapezoid Rule converge quadratically?
Is there a reason why Simpson’s Rule converges like the fourth power of the number of subintervals?
In this series, I hope to answer these questions. While these are standard questions in a introductory college course in numerical analysis, and full and rigorous proofs can be found on Wikipedia and Mathworld, I will approach these questions from the point of view of a bright student who is currently enrolled in calculus and hasn’t yet taken real analysis or numerical analysis.
In this post, we will perform an error analysis for the left-endpoint rule
where is the number of subintervals and is the width of each subinterval, so that .
As noted above, a true exploration of error analysis requires the generalized mean-value theorem, which perhaps a bit much for a talented high school student learning about this technique for the first time. That said, the ideas behind the proof are accessible to high school students, using only ideas from the secondary curriculum, if we restrict our attention to the special case , where is a positive integer.
For this special case, the true area under the curve $f(x) = x^k$ on the subinterval will be
In the above, the shorthand can be formally defined, but here we’ll just take it to mean “terms that have a factor of or higher that we’re too lazy to write out.” Since is supposed to be a small number, these terms will be much smaller in magnitude that the terms that have or and thus can be safely ignored.
Using only the left-endpoint of the subinterval, the left-endpoint approximation of is . Therefore, the error in this approximation will be equal to
.
In the next post of this series, we’ll show that the global error when integrating between and — as opposed to between and — is approximately linear in .
Numerical integration is a standard topic in first-semester calculus. From time to time, I have received questions from students on various aspects of this topic, including:
Why is numerical integration necessary in the first place?
Where do these formulas come from (especially Simpson’s Rule)?
How can I do all of these formulas quickly?
Is there a reason why the Midpoint Rule is better than the Trapezoid Rule?
Is there a reason why both the Midpoint Rule and the Trapezoid Rule converge quadratically?
Is there a reason why Simpson’s Rule converges like the fourth power of the number of subintervals?
In this series, I hope to answer these questions. While these are standard questions in a introductory college course in numerical analysis, and full and rigorous proofs can be found on Wikipedia and Mathworld, I will approach these questions from the point of view of a bright student who is currently enrolled in calculus and hasn’t yet taken real analysis or numerical analysis.
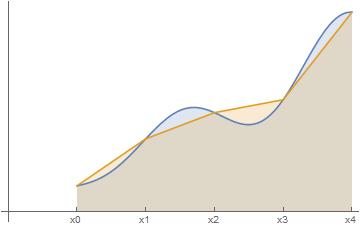
In the previous post in this series, I discussed three different ways of numerically approximating the definite integral , the area under a curve between and .
In this series, we’ll choose equal-sized subintervals of the interval . If is the width of each subinterval so that , then the integral may be approximated as
using left endpoints,
using right endpoints, and
using the midpoints of the subintervals. We have also derived the Trapezoid Rule
and Simpson’s Rule (if is even)
.
In the previous post in this series, we saw that both the left-endpoint and right-endpoint rules have a linear rate of convergence: if twice as many subintervals are taken, then the error appears to go down by a factor of 2. If ten times as many subintervals are used, then the error should go down by a factor of 10. However, both the Midpoint Rule and the Trapezoid Rule have a quadratic rate of convergence: if twice as many subintervals are taken, then the error appears to go down by a factor of 4. If ten times as many subintervals are used, then the error should go down by a factor of 100. Moreover, it appears that the error from the Midpoint Rule is about half that of the Trapezoid Rule if the same number of subintervals are used.
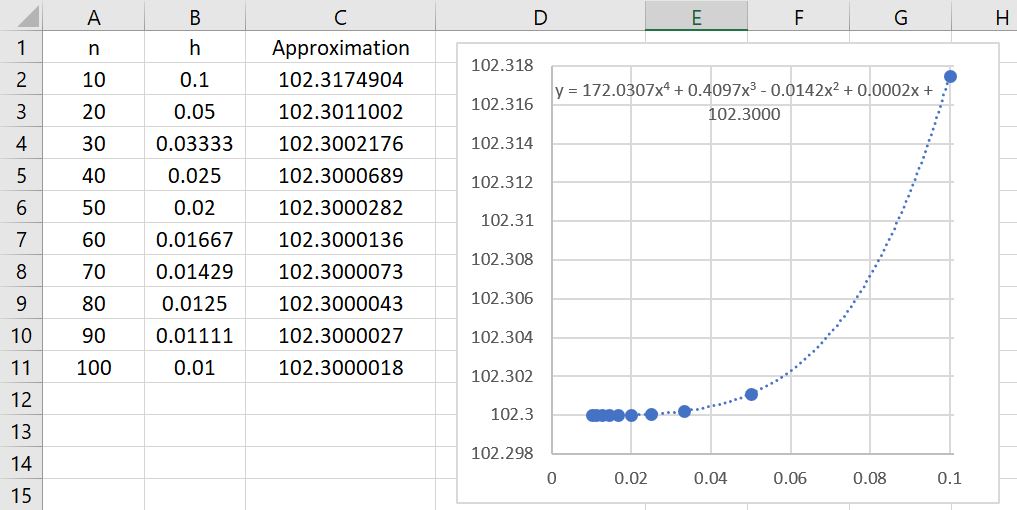
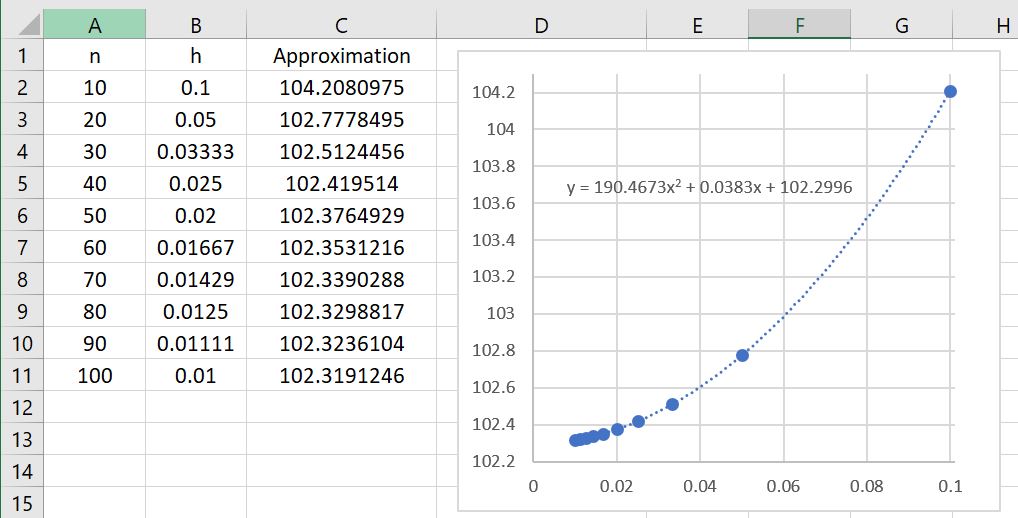
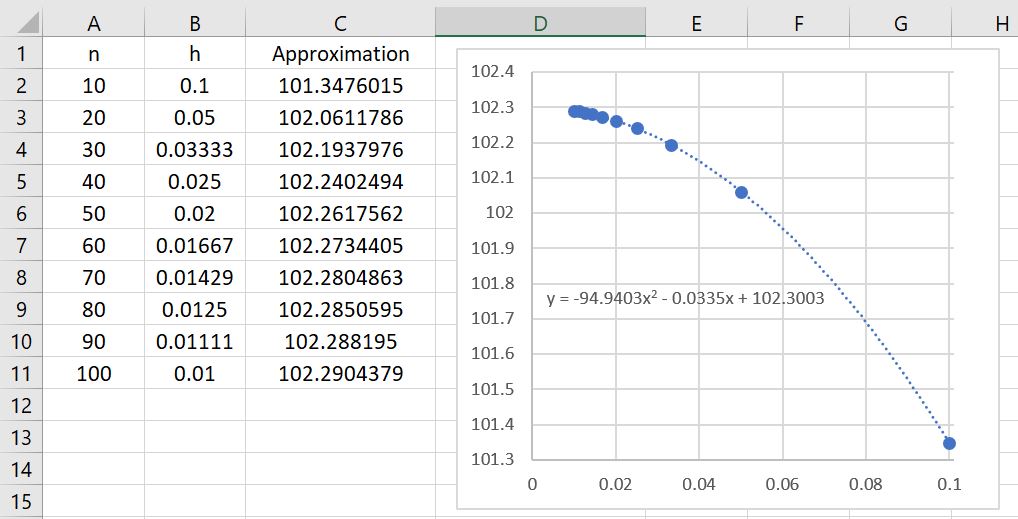
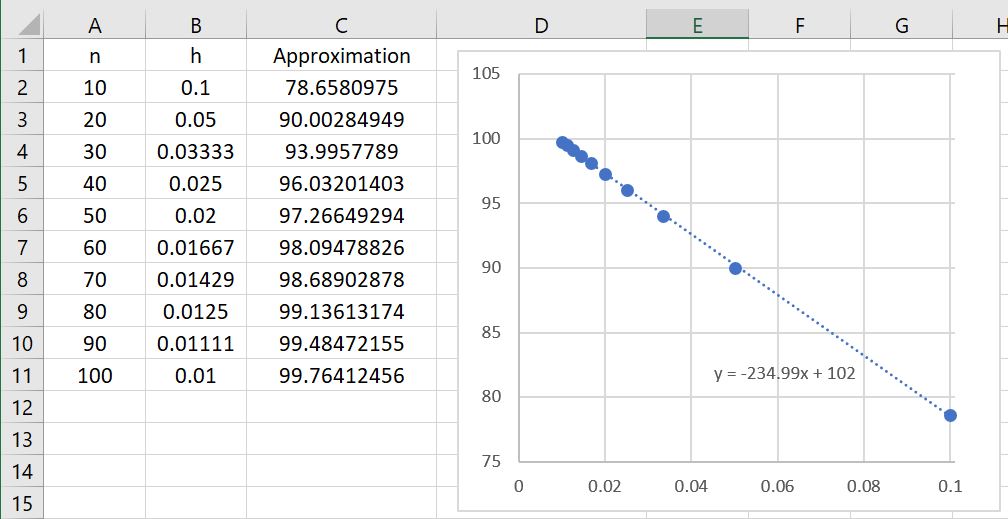
Let’s now explore the results of Simpson’s Rule applied to using different numbers of subintervals. The results are summarized in the table below.
The first immediate observation is that these approximations are far better than even the Midpoint and Trapezoid Rules! Indeed, we see that , using only 20 subintervals, is a better approximation than (from previous posts) either or using 100 subintervals! The lesson to learn again: Simpson’s Rule is a bit more difficult to compute than the Trapezoid Rule or the Midpoint Rule because of the different weights. Nevertheless, choosing a good algorithm is often far better than simply doing lots of computations.
There’s a second observation: the rate of convergence appears to be much, much faster. Indeed, the data points appear to fit a quartic polynomial very well. Said another way, if twice as many subintervals are taken, then the error appears to go down by a factor of 16. We can actually see this in the figure, looking at the lines with 10, 20, 40, and 80 subintervals.
Error with 10 subintervals = .
Error with 20 subintervals = .
Error with 40 subintervals = .
Error with 80 subintervals = .
In all cases, the error on the next line is about the error on the previous line divided by 16.
This illustrates quartic convergence, as opposed to the mere linear convergence of the left- and right-endpoint rules or the quadratic convergence of the Midpoint and Trapezoid Rules.



 ,
,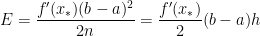 .
.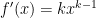 .
.





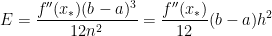
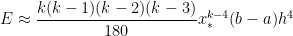
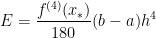

 has an error of
has an error of 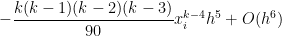 .
.![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=000000&s=0&c=20201002) instead of a subinterval
instead of a subinterval ![[x_i,x_i+2h]](https://s0.wp.com/latex.php?latex=%5Bx_i%2Cx_i%2B2h%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
The total error when approximating
.
The total error when approximating  will be the sum of the errors for the integrals over
will be the sum of the errors for the integrals over ![[x_0,x_2]](https://s0.wp.com/latex.php?latex=%5Bx_0%2Cx_2%5D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, ![[x_2,x_4]](https://s0.wp.com/latex.php?latex=%5Bx_2%2Cx_4%5D&bg=ffffff&fg=000000&s=0&c=20201002) , through
, through ![[x_{n-2},x_n]](https://s0.wp.com/latex.php?latex=%5Bx_%7Bn-2%7D%2Cx_n%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Therefore, the total error will be
. Therefore, the total error will be
 for different numbers of subintervals. If we take
for different numbers of subintervals. If we take  and
and  , then the error should be approximately equal to
, then the error should be approximately equal to
 ,
,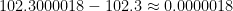 .
.
 , so that the error becomes
, so that the error becomes
 ,
, is the average of the
is the average of the 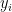 . (We notice that there are only
. (We notice that there are only 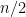 terms in this sum since we’re adding only the even terms.) Clearly, this average is somewhere between the smallest and the largest of the
terms in this sum since we’re adding only the even terms.) Clearly, this average is somewhere between the smallest and the largest of the  is a continuous function, that means that there must be some value of
is a continuous function, that means that there must be some value of 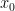 and
and 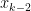 — and therefore between
— and therefore between 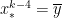 by the Intermediate Value Theorem. We conclude that the error can be written as
by the Intermediate Value Theorem. We conclude that the error can be written as
 ,
, is the length of one subinterval, we see that
is the length of one subinterval, we see that  is the total length of the interval
is the total length of the interval 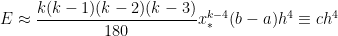 ,
, is determined by
is determined by  . In other words, for the special case
. In other words, for the special case ![\int_a^b f(x) \, dx \approx \frac{h}{3} \left[f(x_0) + 4(x_1) + 2f(x_2) + \dots + 2f(x_{n-2}) + 4f(x_{n-1}) +f(x_n) \right] \equiv T_n](https://s0.wp.com/latex.php?latex=%5Cint_a%5Eb+f%28x%29+%5C%2C+dx+%5Capprox+%5Cfrac%7Bh%7D%7B3%7D+%5Cleft%5Bf%28x_0%29+%2B+4%28x_1%29+%2B+2f%28x_2%29+%2B+%5Cdots+%2B+2f%28x_%7Bn-2%7D%29+%2B+4f%28x_%7Bn-1%7D%29+%2Bf%28x_n%29+%5Cright%5D+%5Cequiv+T_n&bg=ffffff&fg=000000&s=0&c=20201002)
 is the number of subintervals (which has to be even) and
is the number of subintervals (which has to be even) and  is the width of each subinterval, so that
is the width of each subinterval, so that  .
.
 is a positive integer.
is a positive integer.![[x_i, x_i +h]](https://s0.wp.com/latex.php?latex=%5Bx_i%2C+x_i+%2Bh%5D&bg=ffffff&fg=000000&s=0&c=20201002) will be
will be![\displaystyle \int_{x_i}^{x_i+h} x^k \, dx = \frac{1}{k+1} \left[ (x_i+h)^{k+1} - x_i^{k+1} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cint_%7Bx_i%7D%5E%7Bx_i%2Bh%7D+x%5Ek+%5C%2C+dx+%3D+%5Cfrac%7B1%7D%7Bk%2B1%7D+%5Cleft%5B+%28x_i%2Bh%29%5E%7Bk%2B1%7D+-+x_i%5E%7Bk%2B1%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![= \displaystyle \frac{1}{k+1} \left[x_i^{k+1} + {k+1 \choose 1} x_i^k h + {k+1 \choose 2} x_i^{k-1} h^2 + {k+1 \choose 3} x_i^{k-2} h^3 + {k+1 \choose 4} x_i^{k-3} h^4+ {k+1 \choose 5} x_i^{k-4} h^5+ O(h^6) - x_i^{k+1} \right]](https://s0.wp.com/latex.php?latex=%3D+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bk%2B1%7D+%5Cleft%5Bx_i%5E%7Bk%2B1%7D+%2B+%7Bk%2B1+%5Cchoose+1%7D+x_i%5Ek+h+%2B+%7Bk%2B1+%5Cchoose+2%7D+x_i%5E%7Bk-1%7D+h%5E2+%2B+%7Bk%2B1+%5Cchoose+3%7D+x_i%5E%7Bk-2%7D+h%5E3+%2B+%7Bk%2B1+%5Cchoose+4%7D+x_i%5E%7Bk-3%7D+h%5E4%2B+%7Bk%2B1+%5Cchoose+5%7D+x_i%5E%7Bk-4%7D+h%5E5%2B+O%28h%5E6%29+-+x_i%5E%7Bk%2B1%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)

![+ \displaystyle \frac{(k+1)k(k-1)(k-2)(k-3)}{120} x_i^{k-4} h^5 \bigg] + O(h^6)](https://s0.wp.com/latex.php?latex=%2B+%5Cdisplaystyle+%5Cfrac%7B%28k%2B1%29k%28k-1%29%28k-2%29%28k-3%29%7D%7B120%7D+x_i%5E%7Bk-4%7D+h%5E5+%5Cbigg%5D+%2B+O%28h%5E6%29+&bg=ffffff&fg=000000&s=0&c=20201002)
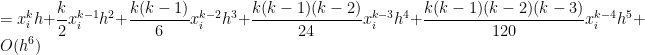
 can be formally defined, but here we’ll just take it to mean “terms that have a factor of
can be formally defined, but here we’ll just take it to mean “terms that have a factor of  or higher that we’re too lazy to write out.” Since
or higher that we’re too lazy to write out.” Since  relating the approximations from Simpson’s Rule, the Midpoint Rule, and the Trapezoid Rule. We now exploit this relationship to approximate
relating the approximations from Simpson’s Rule, the Midpoint Rule, and the Trapezoid Rule. We now exploit this relationship to approximate 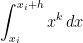 . Earlier in this series, we found the Midpoint Rule approximation on this subinterval to be
. Earlier in this series, we found the Midpoint Rule approximation on this subinterval to be
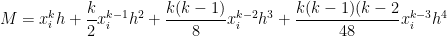

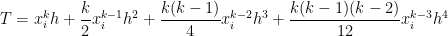
 .
.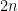 subintervals, the Simpson’s Rule approximation of
subintervals, the Simpson’s Rule approximation of 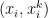 ,
, 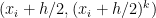 , and
, and  — will be
— will be 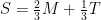 . Since
. Since ,
,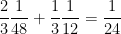 ,
, ,
,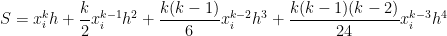
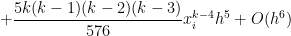 .
. perfectly match the first four terms of the exact value of the integral! Subtracting from the actual integral, the error in this approximation will be equal to
perfectly match the first four terms of the exact value of the integral! Subtracting from the actual integral, the error in this approximation will be equal to
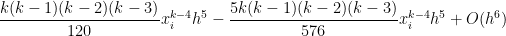
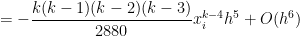
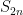 , where
, where 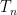 and
and 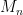 , where only
, where only 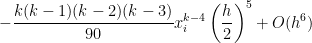 ,
, is the width of all of the
is the width of all of the  , a vast improvement over both the Midpoint Rule and the Trapezoid Rule. This illustrates a general principle of numerical analysis: given two algorithms that are
, a vast improvement over both the Midpoint Rule and the Trapezoid Rule. This illustrates a general principle of numerical analysis: given two algorithms that are  , an improved algorithm can typically be made by taking some linear combination of the two algorithms. Usually, the improvement will be to
, an improved algorithm can typically be made by taking some linear combination of the two algorithms. Usually, the improvement will be to  ; however, in this example, we magically obtained an improvement to
; however, in this example, we magically obtained an improvement to 
![[x_i,x_i+h]](https://s0.wp.com/latex.php?latex=%5Bx_i%2Cx_i%2Bh%5D&bg=ffffff&fg=000000&s=0&c=20201002) . The logic is almost a perfect copy-and-paste from the analysis used for the Midpoint Rule.
The total error when approximating
. The logic is almost a perfect copy-and-paste from the analysis used for the Midpoint Rule.
The total error when approximating ![[x_0,x_1]](https://s0.wp.com/latex.php?latex=%5Bx_0%2Cx_1%5D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, ![[x_1,x_2]](https://s0.wp.com/latex.php?latex=%5Bx_1%2Cx_2%5D&bg=ffffff&fg=000000&s=0&c=20201002) , through
, through ![[x_{n-1},x_n]](https://s0.wp.com/latex.php?latex=%5Bx_%7Bn-1%7D%2Cx_n%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Therefore, the total error will be
. Therefore, the total error will be
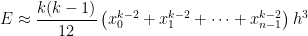 .
.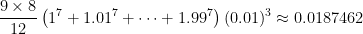 ,
, .
.
 , so that the error becomes
, so that the error becomes
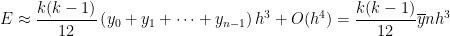 ,
, is the average of the
is the average of the  is a continuous function, that means that there must be some value of
is a continuous function, that means that there must be some value of  — and therefore between
— and therefore between  by the Intermediate Value Theorem. We conclude that the error can be written as
by the Intermediate Value Theorem. We conclude that the error can be written as
 ,
, ,
,![\int_a^b f(x) \, dx \approx \frac{h}{2} \left[f(x_0) + 2f(x_1) + 2f(x_2) + \dots + 2f(x_{n-1}) +f(x_n) \right] \equiv T_n](https://s0.wp.com/latex.php?latex=%5Cint_a%5Eb+f%28x%29+%5C%2C+dx+%5Capprox+%5Cfrac%7Bh%7D%7B2%7D+%5Cleft%5Bf%28x_0%29+%2B+2f%28x_1%29+%2B+2f%28x_2%29+%2B+%5Cdots+%2B+2f%28x_%7Bn-1%7D%29+%2Bf%28x_n%29+%5Cright%5D+%5Cequiv+T_n&bg=ffffff&fg=000000&s=0&c=20201002)
 because I’ll need this later in this series of posts. For now, looking only at the Trapezoid Rule, it will suffice to write this integral as
because I’ll need this later in this series of posts. For now, looking only at the Trapezoid Rule, it will suffice to write this integral as
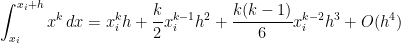 .
.![\displaystyle \frac{h}{2} \left[x_i^k + (x_i + h)^k \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7Bh%7D%7B2%7D+%5Cleft%5Bx_i%5Ek+%2B+%28x_i+%2B+h%29%5Ek+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) , using the width
, using the width  and
and 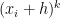 of the trapezoid. Using the Binomial Theorem, this expands as
of the trapezoid. Using the Binomial Theorem, this expands as



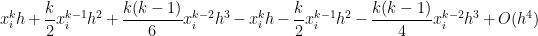

 and
and 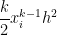 cancel perfectly, leaving us with a local error on the order of
cancel perfectly, leaving us with a local error on the order of 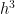 .
We also recall, from the previous post in this series that the local error from the Midpoint Rule was
.
We also recall, from the previous post in this series that the local error from the Midpoint Rule was 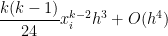 . In other words, while both the Midpoint Rule and Trapezoid Rule have local errors on the order of
. In other words, while both the Midpoint Rule and Trapezoid Rule have local errors on the order of 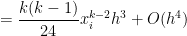
 .
. ,
,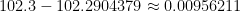 .
.
 ,
,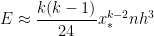 ,
,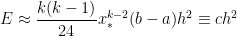 ,
,![\int_a^b f(x) \, dx \approx h \left[f(c_1) + f(c_2) + \dots + f(c_n) \right] \equiv M_n](https://s0.wp.com/latex.php?latex=%5Cint_a%5Eb+f%28x%29+%5C%2C+dx+%5Capprox+h+%5Cleft%5Bf%28c_1%29+%2B+f%28c_2%29+%2B+%5Cdots+%2B+f%28c_n%29+%5Cright%5D+%5Cequiv+M_n&bg=ffffff&fg=000000&s=0&c=20201002)
 is the midpoint of the
is the midpoint of the  th subinterval.
th subinterval.

 . Using the Binomial Theorem, this expands as
. Using the Binomial Theorem, this expands as
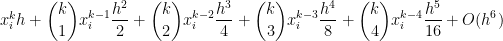



 .
. will be the sum of the errors for the integrals over
will be the sum of the errors for the integrals over  .
. ,
, .
.
 , so that the error becomes
, so that the error becomes
 ,
,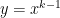 is a continuous function, that means that there must be some value of
is a continuous function, that means that there must be some value of  — and therefore between
— and therefore between 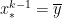 by the Intermediate Value Theorem. We conclude that the error can be written as
by the Intermediate Value Theorem. We conclude that the error can be written as
 ,
, ,
,![\int_a^b f(x) \, dx \approx h \left[f(x_0) + f(x_1) + \dots + f(x_{n-1}) \right] \equiv L_n](https://s0.wp.com/latex.php?latex=%5Cint_a%5Eb+f%28x%29+%5C%2C+dx+%5Capprox+h+%5Cleft%5Bf%28x_0%29+%2B+f%28x_1%29+%2B+%5Cdots+%2B+f%28x_%7Bn-1%7D%29+%5Cright%5D+%5Cequiv+L_n&bg=ffffff&fg=000000&s=0&c=20201002)

![= \displaystyle \frac{1}{k+1} \left[x_i^{k+1} + {k+1 \choose 1} x_i^k h + {k+1 \choose 2} x_i^{k-1} h^2 + O(h^3) - x_i^{k+1} \right]](https://s0.wp.com/latex.php?latex=%3D+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bk%2B1%7D+%5Cleft%5Bx_i%5E%7Bk%2B1%7D+%2B+%7Bk%2B1+%5Cchoose+1%7D+x_i%5Ek+h+%2B+%7Bk%2B1+%5Cchoose+2%7D+x_i%5E%7Bk-1%7D+h%5E2+%2B+O%28h%5E3%29+-+x_i%5E%7Bk%2B1%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![= \displaystyle \frac{1}{k+1} \left[ (k+1) x_i^k h + \frac{(k+1)k}{2} x_i^{k-1} h^2 + O(h^3) \right]](https://s0.wp.com/latex.php?latex=%3D+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bk%2B1%7D+%5Cleft%5B+%28k%2B1%29+x_i%5Ek+h+%2B+%5Cfrac%7B%28k%2B1%29k%7D%7B2%7D+x_i%5E%7Bk-1%7D+h%5E2+%2B+O%28h%5E3%29+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)

 and thus can be safely ignored.
and thus can be safely ignored. and
and 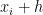 — is approximately linear in
— is approximately linear in  , the area under a curve
, the area under a curve  between
between 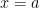 and
and 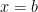 .
.
![\int_a^b f(x) \, dx \approx h \left[f(x_1) + f(x_2) + \dots + f(x_n) \right] \equiv R_n](https://s0.wp.com/latex.php?latex=%5Cint_a%5Eb+f%28x%29+%5C%2C+dx+%5Capprox+h+%5Cleft%5Bf%28x_1%29+%2B+f%28x_2%29+%2B+%5Cdots+%2B+f%28x_n%29+%5Cright%5D+%5Cequiv+R_n&bg=ffffff&fg=000000&s=0&c=20201002)
![\int_a^b f(x) \, dx \approx \displaystyle \frac{h}{2} [f(x_0) + 2f(x_1) + \dots + 2f(x_{n-1}) + f(x_n)] \equiv T_n](https://s0.wp.com/latex.php?latex=%5Cint_a%5Eb+f%28x%29+%5C%2C+dx+%5Capprox+%5Cdisplaystyle+%5Cfrac%7Bh%7D%7B2%7D+%5Bf%28x_0%29+%2B+2f%28x_1%29+%2B+%5Cdots+%2B+2f%28x_%7Bn-1%7D%29+%2B+f%28x_n%29%5D+%5Cequiv+T_n&bg=ffffff&fg=000000&s=0&c=20201002)
![\int_a^b f(x) \, dx \approx \displaystyle \frac{h}{3} \left[y_0 + 4 y_1 + 2 y_2 + 4 y_3 + \dots + 2y_{n-2} + 4 y_{n-1} + y_{n} \right] \equiv S_n](https://s0.wp.com/latex.php?latex=%5Cint_a%5Eb+f%28x%29+%5C%2C+dx+%5Capprox+%5Cdisplaystyle+%5Cfrac%7Bh%7D%7B3%7D+%5Cleft%5By_0+%2B+4+y_1+%2B+2+y_2+%2B+4+y_3+%2B+%5Cdots+%2B+2y_%7Bn-2%7D+%2B+4+y_%7Bn-1%7D+%2B%C2%A0+y_%7Bn%7D+%5Cright%5D+%5Cequiv+S_n&bg=ffffff&fg=000000&s=0&c=20201002) .
. using different numbers of subintervals. The results are summarized in the table below.
using different numbers of subintervals. The results are summarized in the table below. , using only 20 subintervals, is a better approximation than (from previous posts) either
, using only 20 subintervals, is a better approximation than (from previous posts) either 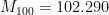 or
or  using 100 subintervals! The lesson to learn again: Simpson’s Rule is a bit more difficult to compute than the Trapezoid Rule or the Midpoint Rule because of the different weights. Nevertheless, choosing a good algorithm is often far better than simply doing lots of computations.
using 100 subintervals! The lesson to learn again: Simpson’s Rule is a bit more difficult to compute than the Trapezoid Rule or the Midpoint Rule because of the different weights. Nevertheless, choosing a good algorithm is often far better than simply doing lots of computations.  .
. .
. .
. .
.