Let
be the set of all things,
be the statement “
is holding back our dreams,” and
be the statement “We are going to let go of

This matches a line from “Somebody” by Lemonade Mouth.

Context: Part of a discrete mathematics course includes an introduction to predicate and propositional logic for our math majors. As you can probably guess from their names, students tend to think these concepts are dry and uninteresting even though they’re very important for their development as math majors.
In an effort to making these topics more appealing, I spent a few days mining the depths of popular culture in a (likely futile) attempt to make these ideas more interesting to my students. In this series, I’d like to share what I found. Naturally, the sources that I found have varying levels of complexity, which is appropriate for students who are first learning prepositional and predicate logic.
When I actually presented these in class, I either presented the logical statement and had my class guess the statement in actual English, or I gave my students the famous quote and them translate it into predicate logic. However, for the purposes of this series, I’ll just present the statement in predicate logic first.
 be the statement “Our ideas held no water,” and let
be the statement “Our ideas held no water,” and let  be the statement “We used them like a dam.” Translate the logical statement
be the statement “We used them like a dam.” Translate the logical statement
 be the set of all people, and let
be the set of all people, and let 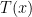 be the statement “
be the statement “
 be the statement “
be the statement “

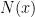 be the statement “
be the statement “
 be the set of all animals, and let
be the set of all animals, and let 
 be the statement “The sun fears the reaper,” and let
be the statement “The sun fears the reaper,” and let  be the statement “The rain fears the reaper.” Translate the logical statement
be the statement “The rain fears the reaper.” Translate the logical statement
