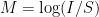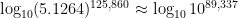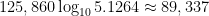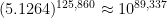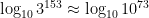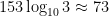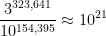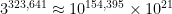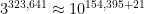Source: https://xkcd.com/3049/
Source: https://xkcd.com/3049/

I’m doing something that I should have done a long time ago: collect past series of posts into a single, easy-to-reference post. The following posts formed my series on computing square roots and logarithms without a calculator (with the latest post added).
Part 1: Method #1: Trial and error.
Part 2: Method #2: An algorithm comparable to long division.
Part 3: Method #3: Introduction to logarithmic tables.
Part 4: Finding antilogarithms with a table.
Part 5: Pedagogical and historical thoughts on log tables.
Part 6: Computation of square roots using a log table.
Part 7: Method #4: Slide rules
Part 8: Method #5: By hand, using a couple of known logarithms base 10, the change of base formula, and the Taylor approximation 
Part 9: An in-class activity for getting students comfortable with logarithms when seen for the first time.
Part 10: Method #6: Mentally… anecdotes from Nobel Prize-winning physicist Richard P. Feynman and me.
Part 11: Method #7: Newton’s Method.
Part 12: Method #8: The formula
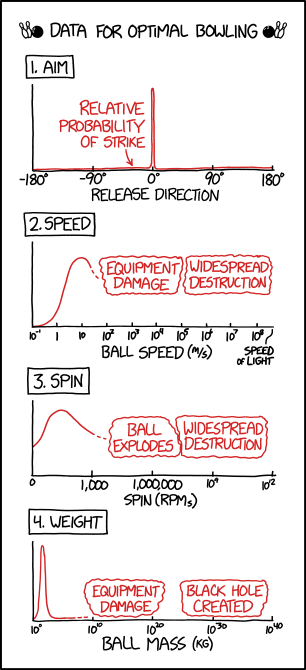
Source: https://xkcd.com/2711/
In my capstone class for future secondary math teachers, I ask my students to come up with ideas for engaging their students with different topics in the secondary mathematics curriculum. In other words, the point of the assignment was not to devise a full-blown lesson plan on this topic. Instead, I asked my students to think about three different ways of getting their students interested in the topic in the first place.
I plan to share some of the best of these ideas on this blog (after asking my students’ permission, of course).
This student submission comes from my former student Jonathan Chen. His topic, from Precalculus: computing logarithms with base 10.
![]()
What interesting (i.e., uncontrived) word problems using this topic can your students do now?
Computing logarithms with base 10 can appear in many scientific applications for word problems. To define the acidity or alkalinity of a substance, Chemists use the formula ![pH = \log [H^+]](https://s0.wp.com/latex.php?latex=pH+%3D+%5Clog+%5BH%5E%2B%5D&bg=ffffff&fg=000000&s=0&c=20201002)

![]()
How can this topic be used in your students’ future courses in mathematics or science?
As shown in the above answer, this topic can reappear in student’s future science course in the topic of pH levels, earthquake intensity, or “loudness” measured in decibels. In order to find the pH levels, [H+] concentration, or the [OH–] concentration you may need to know how to calculate logarithms with base 10 when dealing with the equation
![]()
How was this topic adopted by the mathematical community?
Calculating logarithms with base 10 has been around since 1614. John Napier invented logarithms and ever since then small additions have been made. Additions such as a logarithmic table made it easier to solve logarithmic problems. The logarithmic tables are similar to the multiplication tables elementary schoolers memorize to calculate simple multiplication faster for their future problems. Many mathematicians made their contributions to add more to the logarithmic table to the point where the calculations reached up to 200,000. Aside from the logarithmic tables, there were other methods to calculate logarithms with base 10 such as the slide rule. It was also possible to memorize the values of the logs with base 10 of 1 through 10 and use the logarithmic rules to calculate bigger values. Because
by expansion and logarithmic rules, people can solve this problem my memorizing that 
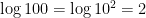
References
“The Log Log Duplex Trig” “Slide Rule”. (n.d.). Retrieved from Web Archive: https://web.archive.org/web/20090214020502/http://www.mccoys-kecatalogs.com/K%26EManuals/4081-3_1943/4081-3_1943.htm
Bourne, M. (n.d.). 4. Logarithms to Base 10. Retrieved from Interactive Mathematics: https://www.intmath.com/exponential-logarithmic-functions/4-logs-base-10.php
Calculating Base 10 Logarithms in your Head. (n.d.). Retrieved from Nerd Paradise: https://nerdparadise.com/math/base10logs
John Napier and the invention of logarithms, 1614; a lecture. (n.d.). Retrieved from Archive.org: https://archive.org/details/johnnapierinvent00hobsiala/page/18/mode/2up
Stapel, E. (n.d.). Logarithmic Word Problems. Retrieved from Purple Math: https://www.purplemath.com/modules/expoprob.htm
In my capstone class for future secondary math teachers, I ask my students to come up with ideas for engaging their students with different topics in the secondary mathematics curriculum. In other words, the point of the assignment was not to devise a full-blown lesson plan on this topic. Instead, I asked my students to think about three different ways of getting their students interested in the topic in the first place.
I plan to share some of the best of these ideas on this blog (after asking my students’ permission, of course).
This student submission comes from my former student Andrew Sansom. His topic, from Precalculus: computing logarithms with base 10.
![]()
D1. How can technology (YouTube, Khan Academy [khanacademy.org], Vi Hart, Geometers Sketchpad, graphing calculators, etc.) be used to effectively engage students with this topic?
The slide rule was originally invented around 1620, shortly after Napier invented the logarithm. In its simplest form, it uses two logarithmic scales that slide past each other, allowing one to multiply and divide numbers easily. If the scales were linear, aligning them would add two numbers together, but the logarithmic scale turns this into a multiplication problem. For example, the below configuration represents the problem: 

Because of log rules, the above problem can be represented as:
The C-scale is aligned against the 14 on the D-scale. The reticule is then translated so that it is over the 18 on the C-scale. The sum of the log of these two values is the log of their product.
Most modern students have never seen a slide rule before, and those that have heard of one probably know little about it other than the cliché “we put men on the moon using slide rules!” Consequently, there these are quite novel for students. A particularly fun, engaging activity to demonstrate to students the power of logarithms would be to challenge volunteers to a race. The student must multiply two three-digit numbers on the board, while the teacher uses a slide rule to do the same computation. Doubtless, a proficient slide rule user will win every time. This activity can be done briefly but will energize the students and show them that there may be something more to this “whole logarithm idea” instead of some abstract thing they’ll never see again.
![]()
How can this topic be used in your students’ future courses in mathematics or science?
Computing logarithms with base 10, especially with using logarithm properties, easily leads to learning to compute logarithms in other bases. This generalizes further to logarithmic functions, which are one of the concepts from precalculus most useful in calculus. Integrals with rational functions usually become problems involving logarithms and log properties. Without mastery of the aforementioned rudimentary skills, the student is quickly doomed to be unable to handle those problems. Many limits, including the limit definition of e, Euler’s number, cannot be evaluated without logarithms.
Outside of pure math classes, the decibel is a common unit of measurement in quantities that logarithmic scales with base 10. It is particularly relevant in acoustics and circuit analysis, both topics in physics classes. In chemistry, the pH of a solution is defined as the negative base-ten logarithm of the concentration of hydrogen ions in that solution. Acidity is a crucially important topic in high school chemistry.
![]()
A1. What interesting (i.e., uncontrived) word problems using this topic can your students do now?
Many word problems could be easily constructed involving computations of logarithms of base 10. Below is a problem involving earthquakes and the Richter scale. It would not be difficult to make similar problems involving the volume of sounds, the signal to noise ratio of signals in circuits, or the acidity of a solution.
The Richter Scale is used to measure the strength of earthquakes. It is defined as
where 


Solution:
First, substitute our known quantity into the equation.
Next, solve for the intensity of the Rat Island quake.
Now, substitute the intensity of the new quake into the original equation.
Thus, the new quake has magnitude 8.393 on the Richter scale.
References:
Earthquake data from Wikipedia’s List of Earthquakes (https://en.wikipedia.org/wiki/Lists_of_earthquakes#Largest_earthquakes_by_magnitude)
Slide rule picture is a screenshot of Derek Ross’s Virtual Slide Rule (http://www.antiquark.com/sliderule/sim/n909es/virtual-n909-es.html)
I’m doing something that I should have done a long time ago: collecting a series of posts into one single post. The following links comprised my series on the decimal expansions of logarithms.
Part 1: Pedagogical motivation: how can students develop a better understanding for the apparently random jumble of digits in irrational logarithms?
Part 2: Idea: use large powers.
Part 3: Further idea: use very large powers.
Part 4: Connect to continued fractions and convergents.
Part 5: Tips for students to find these very large powers.
While some common (i.e., base-10) logarithms work out evenly, like 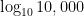

In today’s post, I’ll summarize the past few posts to describe how talented Algebra II students, who have just been introduced to logarithms, can develop proficiency with the Laws of Logarithms while also understanding that the above answer is not just a meaningless jumble of digits. The only tools students will need are
![]()
To estimate 
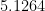
One way to do this is to use Wolfram Alpha to find the convergents of
Convergents[Log[10,5.1264],15]
A little explanation is in order:
 should be used for natural logarithms instead of
should be used for natural logarithms instead of  , as base-10 logarithms are next to useless for mathematical researchers. That said, I freely concede that this convention is confusing to students who grew up thinking that should be used for base-10 logarithms and for natural logarithms. (See also my standard joke about using natural logarithms.) Naturally, the can be changed for other logarithms.. In most cases, that’s enough terms to provide a convergent whose denominator is at least six digits long. In the rare instance when this doesn’t happen, a number larger than 15 can be entered.
, as base-10 logarithms are next to useless for mathematical researchers. That said, I freely concede that this convention is confusing to students who grew up thinking that should be used for base-10 logarithms and for natural logarithms. (See also my standard joke about using natural logarithms.) Naturally, the can be changed for other logarithms.. In most cases, that’s enough terms to provide a convergent whose denominator is at least six digits long. In the rare instance when this doesn’t happen, a number larger than 15 can be entered.From Wolfram Alpha, I see that 
for an easy approximation on a scientific calculation will be  . In this context, “best” means something that’s close to a power of 10 but less than
. In this context, “best” means something that’s close to a power of 10 but less than  . Students entering into a calculator will find
. Students entering into a calculator will findIn other words, the denominator of the convergent
A quick check with a calculator shows that this approximation is accurate to three decimal places. This alone should convince many students that the above apparently random jumble of digits is not so random after all.
![]()
While the above discussion should be enough for many students, some students may want to know how to find the rest of the decimal places with this technique. To answer this question, we again turn to the convergents of 
Option #1. Ask the student to use Wolfram Alpha to raise 

which matches the output of the calculator.
Option #2. Ask the student to “trick” a hand-held calculator into finding 
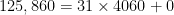 . (This is a rare case where there happens to be no remainder.) Next, the student uses a hand-held calculate to compute
. (This is a rare case where there happens to be no remainder.) Next, the student uses a hand-held calculate to computeIn this example, the 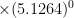


which may be rearranged as
after using the Laws of Exponents. From this point, the derivation follows the steps in Option #1.
While some common (i.e., base-10) logarithms work out evenly, like
To a student first learning logarithms, the answer is just an apparently random jumble of digits; indeed, it can proven that the answer is irrational. With a little prompting, a teacher can get his/her students wondering about how people 50 years ago could have figured this out without a calculator. This leads to a natural pedagogical question:
Can good Algebra II students, using only the tools at their disposal, understand how decimal expansions of base-10 logarithms could have been found before computers were invented?
Here’s a trial-and-error technique — an exploration activity — that is within the grasp of Algebra II students. It’s simple to understand; it’s just a lot of work. The only tools that are needed are
 by itself repeatedly in a quest to find integer powers of that are close to powers of
by itself repeatedly in a quest to find integer powers of that are close to powers of 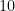 .
.![]()
In the previous post in this series, we found that
and

Using the Laws of Logarithms on the latter provides an approximation of 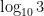

Compare with:
Since hand-held calculators will generate identical outputs for these two expressions (up to the display capabilities of the calculator), this may lead to the misconception that the irrational number 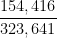
![]()
We now turn to a question that was deferred in the previous post.
Student: How did you know to raise 3 to the 323,641st power?
Teacher: I just multiplied 3 by itself a few hundred thousand times.
Student: C’mon, really. How did you know?
While I don’t doubt that some of our ancestors used this technique to find logarithms — at least before the discovery of calculus — today’s students are not going to be that patient. Instead, to find suitable powers quickly, we will use ideas from the mathematical theory of continued fractions: see Wikipedia, Mathworld, or this excellent self-contained book for more details.
To approximate 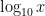



or, equivalently,

In other words, we’re looking for rational numbers that are reasonable close to
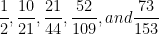
A larger convergent is 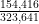
As more terms are taken, these convergents get closer and closer to
using a denominator that’s less than the denominator of the next convergent. For example, the second convergent  is the closest rational number to that has a denominator less than
is the closest rational number to that has a denominator less than  , the denominator of the third convergent. and slightly less than .
, the denominator of the third convergent. and slightly less than . is guaranteed to be within
is guaranteed to be within  of . (In fact, if and
of . (In fact, if and 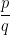 are consecutive convergents, then is guaranteed to be within
are consecutive convergents, then is guaranteed to be within  of .) is at least six digits long (that is, greater than
of .) is at least six digits long (that is, greater than  ), then must be within
), then must be within  of … and it’ll probably be significantly closer than that.
of … and it’ll probably be significantly closer than that.So convergents provide a way for teachers to maintain the illusion that they found a power like 
While some common (i.e., base-10) logarithms work out evenly, like
To a student first learning logarithms, the answer is just an apparently random jumble of digits; indeed, it can proven that the answer is irrational. With a little prompting, a teacher can get his/her students wondering about how people 50 years ago could have figured this out without a calculator. This leads to a natural pedagogical question:
Can good Algebra II students, using only the tools at their disposal, understand how decimal expansions of base-10 logarithms could have been found before computers were invented?
Here’s a trial-and-error technique — an exploration activity — that is within the grasp of Algebra II students. It’s simple to understand; it’s just a lot of work.
To approximate
![]()
In the previous post in this series, we essentially used trial and error to find such powers of 3. We found

from which we can conclude

This approximation is accurate to five decimal places.
By now, I’d imagine that our student would be convinced that logarithms aren’t just a random jumble of digits… there’s a process (albeit a complicated process) for obtaining these decimal expansions. Of course, this process isn’t the best process, but it works and it only uses techniques at the level of an Algebra II student who’s learning about logarithms for the first time.
If nothing else, hopefully this lesson will give students a little more appreciation for their ancestors who had to perform these kinds of calculations without the benefit of modern computing.
We also saw in the previous post that larger powers can result in better and better approximation. Finding suitable powers gets harder and harder as the exponent gets larger. However, when a better approximation is found, the improvement can be dramatic. Indeed, the decimal expansion of a logarithm can be obtained up to the accuracy of a hand-held calculator with a little patience. For example, let’s compute
Predictably, the complaint will arise: “How did you know to try 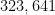
I’ll give the real answer that question later in this series.
Postponing the answer to that question for now, there are a couple ways for students to compute this using readily available technology. Perhaps the most user-friendly is the free resource Wolfram Alpha:
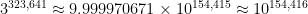
That said, students can also perform this computation by creatively using their handheld calculators. Most calculators will return an overflow error if a direct computation of 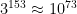


In particular, let’s divide

or

This suggests that we try to compute

and a hand-held calculator can be used to show that this expression is approximately equal to 
By the Laws of Exponents, we see that
![]() Whichever technique is used, we can now use the Laws of Logarithms to approximate
Whichever technique is used, we can now use the Laws of Logarithms to approximate
This approximation matches the decimal expansion of
Since hand-held calculators will generate identical outputs for these two expressions (up to the display capabilities of the calculator), this may lead to the misconception that the irrational number
![]()
Summarizing, Algebra II students can find the decimal expansion of
by itself repeatedly in a quest to find integer powers of that are close to powers of .While I don’t have a specific reference, I’d be stunned if none of our ancestors tried something along these lines in the years between the discovery of logarithms (1614) and calculus (1666 or 1684).