In my capstone class for future secondary math teachers, I ask my students to come up with ideas for engaging their students with different topics in the secondary mathematics curriculum. In other words, the point of the assignment was not to devise a full-blown lesson plan on this topic. Instead, I asked my students to think about three different ways of getting their students interested in the topic in the first place.
I plan to share some of the best of these ideas on this blog (after asking my students’ permission, of course).
This student submission again comes from my former student Lydia Rios. Her topic, from Algebra: defining a function of one variable.

How does this topic extend what your students should have learned in previous courses?
From Prekindergarten and up, students have been practicing skills that prepared them from the concepts of a function. By counting they knew that they were adding that same number to every other number in the same sequence. By doing 1,2,3,4,5,… counting by ones they realized that every left number was being added by one to get the right number. They were taking the input 2 and doing the operation of addition by 1 to get the output of 3. The same thing was happening for other counting sequences, or even general operation statements such as 1+7=8. They have been building up to the idea of functions without recognizing that they were. You can use this no simple idea that’s been installed in them to understand what functions are. You can build them up from here and then start giving them statements with a missing component so they can find a missing variable. Then finally, building them towards defining a function where you give them similar statements with a missing component so that they can start writing out their own equations. *Don’t forget to introduce input and output and that are function represent the relationship between out input (x) is having this operation done to it to get our output (y).
Mathematics Vertical Alignment, Prekindergarten-Grade 2 (texas.gov)
Introduction to Functions | Boundless Algebra (lumenlearning.com)
How has this topic appeared in pop culture (movies, TV, current music, video games, etc.)?
You could use different appearances in pop culture to get students to understand input and output, such as when you are playing video games you are putting your input on the controller to get the output on the screen. However, this may not have an association with function unless you want to start getting into detail about programming. Therefore, to bring about the topic of functions I would just use a word problem that associates with pop culture. You could also bring the business side of pop culture into the class, such as setting up an equation that shows how the more tickets bought makes and increased revenue for the production of a movie. For example, lets say a ticket cost $8.50 and the production get’s 40% of the profit. Then you could set up the equal as 0.40(8.5X)=Y with 0.40 representing 40% of the profit that the production team will receive of the $8.50 tickets.
How has this topic appeared in high culture (art, classical music, theatre, etc.)?
The topic of inputs and outputs can be touched on in reference to theatre. Both in lighting and sound, inputs and outputs are used. Therefore, the concept of this can be taught to the students. For lighting, you can talk about DMX which is what LED lights use so that the technology in the lights can pick up the functions that the computer is telling it to do. You connect the DMX in cord to the DMX in into the lighting board and then the DMX out of the lighting board to the DMX out on the lights. The same idea works with audio. However, the inputs are the microphones and the outputs are the speakers. You would take the microphone aux cord and plug that into the inputs on the Sound Board and then you would take the speaker cord and plug that into the outputs on the Sound Board. Therefore, that particular microphone is connected to that speaker and will only come out of that speaker.
“Welcome to Coolmath.” Cool Math – Free Online Cool Math Lessons, Cool Math Games & Apps, Fun Math Activities, Pre-Algebra, Algebra, Precalculus, www.coolmath.com/algebra/15-functions.
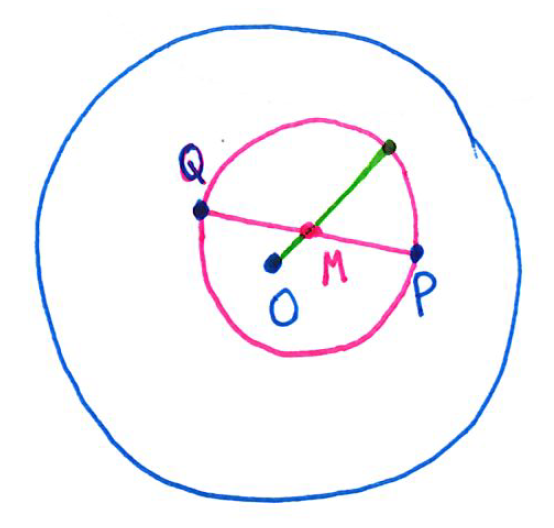
and
are chosen at random (uniformly) from the interior of a unit circle. What is the probability that the circle whose diameter is segment
lies entirely in the interior of the unit circle?






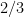






 cannot be expressed using finitely many elementary functions. Therefore, we must resort to numerical methods instead.
cannot be expressed using finitely many elementary functions. Therefore, we must resort to numerical methods instead.


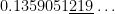

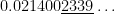
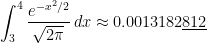
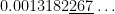
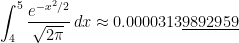

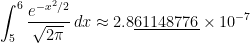

 subintervals provides a better approximation to
subintervals provides a better approximation to  than the normalcdf function.
than the normalcdf function.