- Why is numerical integration necessary in the first place?
- Where do these formulas come from (especially Simpson’s Rule)?
- How can I do all of these formulas quickly?
- Is there a reason why the Midpoint Rule is better than the Trapezoid Rule?
- Is there a reason why both the Midpoint Rule and the Trapezoid Rule converge quadratically?
- Is there a reason why Simpson’s Rule converges like the fourth power of the number of subintervals?

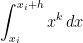 was equal to
was equal to

![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=000000&s=0&c=20201002) and not just a particular subinterval.
and not just a particular subinterval. will be the sum of the errors for the integrals over
will be the sum of the errors for the integrals over ![[x_0,x_1]](https://s0.wp.com/latex.php?latex=%5Bx_0%2Cx_1%5D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, ![[x_1,x_2]](https://s0.wp.com/latex.php?latex=%5Bx_1%2Cx_2%5D&bg=ffffff&fg=000000&s=0&c=20201002) , through
, through ![[x_{n-1},x_n]](https://s0.wp.com/latex.php?latex=%5Bx_%7Bn-1%7D%2Cx_n%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Therefore, the total error will be
. Therefore, the total error will be

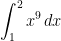 for different numbers of subintervals. If we take
for different numbers of subintervals. If we take  and
and  , then the error should be approximately equal to
, then the error should be approximately equal to

 .
.
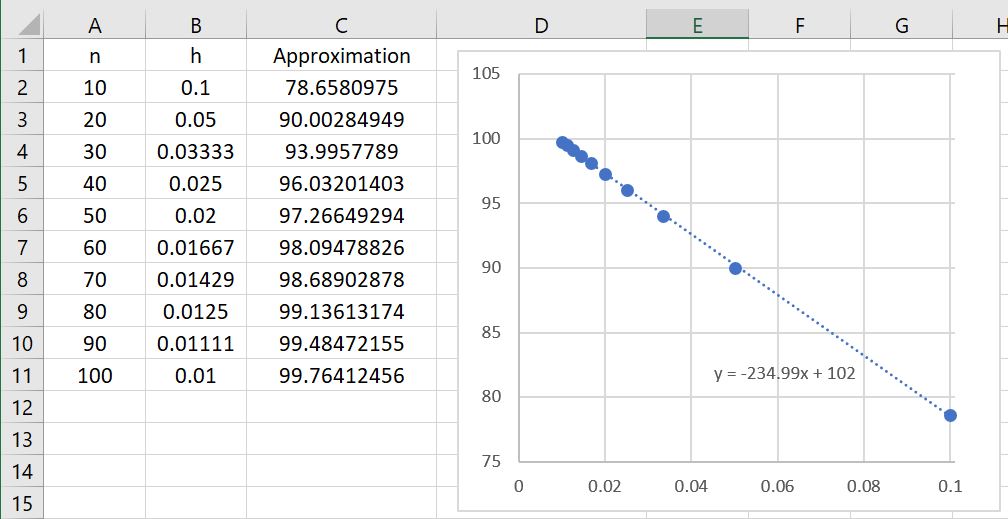
 , so that the error becomes
, so that the error becomes

 is the average of the
is the average of the 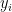 . Clearly, this average is somewhere between the smallest and the largest of the . Since
. Clearly, this average is somewhere between the smallest and the largest of the . Since 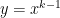 is a continuous function, that means that there must be some value of
is a continuous function, that means that there must be some value of 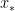 between
between 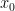 and
and  — and therefore between
— and therefore between  and
and  — so that
— so that 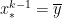 by the Intermediate Value Theorem. We conclude that the error can be written as
by the Intermediate Value Theorem. We conclude that the error can be written as

 is the length of one subinterval, we see that
is the length of one subinterval, we see that  is the total length of the interval . Therefore,
is the total length of the interval . Therefore,

 is determined by , , and
is determined by , , and  . In other words, for the special case
. In other words, for the special case  , we have established that the error from the left-endpoint rule is approximately linear in — without resorting to the generalized mean-value theorem.
, we have established that the error from the left-endpoint rule is approximately linear in — without resorting to the generalized mean-value theorem.

One thought on “Thoughts on Numerical Integration (Part 13): Left endpoint rule and global rate of convergence”