The following problem appeared in Volume 97, Issue 3 (2024) of Mathematics Magazine.
Two points
and
are chosen at random (uniformly) from the interior of a unit circle. What is the probability that the circle whose diameter is segment
lies entirely in the interior of the unit circle?
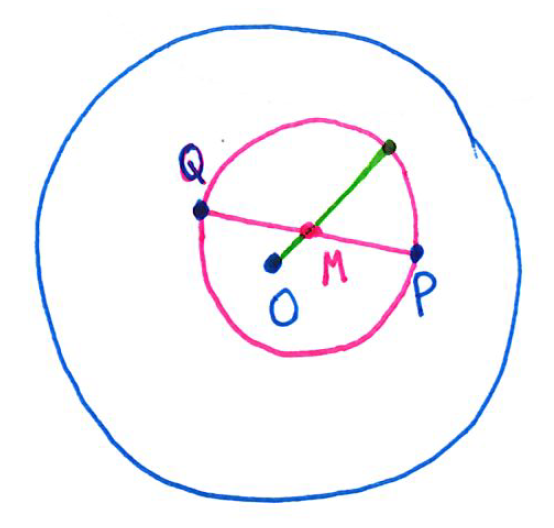
It took me a while to wrap my head around the statement of the problem. In the figure, the points 

The pink circle will lie entirely the blue circle exactly when the green line containing the origin 


As a first step toward wrapping my head around this problem, I programmed a simple simulation in Mathematica to count the number of times that

In the above simulation, out of about 61,000,000 attempts, 66.6644% of the attempts were successful. This leads to the natural guess that the true probability is 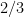


I end with a quick programming note. This certainly isn’t the ideal way to perform the simulation. First, for a fast simulation, I should have programmed in C++ or Python instead of Mathematica. Second, the coordinates of 

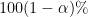 confidence interval for a proportion:
confidence interval for a proportion: .
. is large enough, then
is large enough, then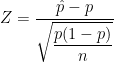
 is the true population proportion and
is the true population proportion and 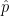 is the sample proportion from a sample of size
is the sample proportion from a sample of size 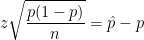
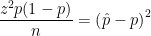






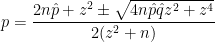


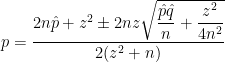
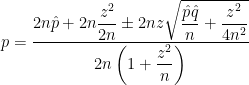
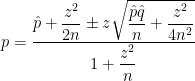
 or
or  ) can be found by using the formula (Observed – Expected)/(Standard Error), where the standard error formula has changed, and the critical values of the normal or
) can be found by using the formula (Observed – Expected)/(Standard Error), where the standard error formula has changed, and the critical values of the normal or