A standard topic in my statistics class is political polling, which is the canonical example of constructing a confidence interval with a relatively small sample to (hopefully) project the opinions of a large population. Of course, polling is only valid if the sample represents the population at large. This is a natural engagement activity in the fall semester preceding a presidential election.
A recent article on FiveThirtyEight.com, “Are Bad Pollsters Copying Good Pollsters,” does a nice job of explaining some of the nuts and bolts of political polling in an age when selected participants are increasingly unlikely to participate… and also raises the specter of how pollsters using nontraditional methods might consciously or subconconsciously cheating. A sample (pun intended) from the article:
What’s a nontraditional poll? One that doesn’t abide by the industry’s best practices. So, a survey is nontraditional if it:
- doesn’t follow probability sampling;
- doesn’t use live interviewers;
- is released by a campaign or campaign groups (because these only selectively release data);
- doesn’t disclose (i.e. doesn’t release raw data to the Roper Archives, isn’t a member of the National Council on Public Polls, or hasn’t signed onto the American Association for Public Opinion Research transparency initiative).
Everything else is a gold-standard poll…
Princeton University graduate student Steven Rogers and Vanderbilt University professor of political science Joshua Clinton [studied] interactive voice response (IVR) surveys in the 2012 Republican presidential primary. (IVR pollsters are in our nontraditional group.) Rogers and Clinton found that IVR pollsters were about as accurate as live-interview pollsters in races where live-interview pollsters surveyed the electorate. IVR pollsters were considerably less accurate when no live-interview poll was conducted. This effect held true even when controlling for a slew of different variables. Rogers and Clinton suggested that the IVR pollsters were taking a “cue” from the live pollsters in order to appear more accurate.
My own analysis hints at the same possibility. The nontraditional pollsters did worse in races without a live pollster.
 of two means, where at least one mean does not arise from a small sample, the Student t distribution must be employed. In particular, the number of degrees of freedom for the Student t distribution must be computed. Many textbooks suggest using
of two means, where at least one mean does not arise from a small sample, the Student t distribution must be employed. In particular, the number of degrees of freedom for the Student t distribution must be computed. Many textbooks suggest using 
 is the standard error associated with the first average
is the standard error associated with the first average 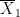 , where
, where  (if known) is the population standard deviation for
(if known) is the population standard deviation for  and
and 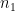 is the number of samples that are averaged to find
is the number of samples that are averaged to find  is employed.
is employed. and
and 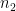 are similarly defined for the average
are similarly defined for the average  .
. in the numerator is equal to
in the numerator is equal to  . This is the square of the standard error
. This is the square of the standard error  associated with the difference
associated with the difference 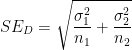 .
. ,
,
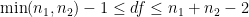 .
.![df = \left( \displaystyle \frac{1}{n_1-1} \left[ \frac{SE_1^2}{SE_1^2 + SE_2^2}\right]^2 + \frac{1}{n_2-1} \left[ \frac{SE_2^2}{SE_1^2 + SE_2^2} \right]^2 \right)^{-1}](https://s0.wp.com/latex.php?latex=df+%3D+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bn_1-1%7D+%5Cleft%5B+%5Cfrac%7BSE_1%5E2%7D%7BSE_1%5E2+%2B+SE_2%5E2%7D%5Cright%5D%5E2+%2B+%5Cfrac%7B1%7D%7Bn_2-1%7D+%5Cleft%5B+%5Cfrac%7BSE_2%5E2%7D%7BSE_1%5E2+%2B+SE_2%5E2%7D+%5Cright%5D%5E2+%5Cright%29%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 and
and  , so that
, so that![df = \left( \displaystyle \frac{1}{m_1} \left[ \frac{SE_1^2}{SE_1^2 + SE_2^2}\right]^2 + \frac{1}{m_2} \left[ \frac{SE_2^2}{SE_1^2 + SE_2^2} \right]^2 \right)^{-1}](https://s0.wp.com/latex.php?latex=df+%3D+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bm_1%7D+%5Cleft%5B+%5Cfrac%7BSE_1%5E2%7D%7BSE_1%5E2+%2B+SE_2%5E2%7D%5Cright%5D%5E2+%2B+%5Cfrac%7B1%7D%7Bm_2%7D+%5Cleft%5B+%5Cfrac%7BSE_2%5E2%7D%7BSE_1%5E2+%2B+SE_2%5E2%7D+%5Cright%5D%5E2+%5Cright%29%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 . All of these terms are nonnegative (and, in practice, they’re all positive), so that
. All of these terms are nonnegative (and, in practice, they’re all positive), so that 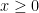 . Also, the numerator is no larger than the denominator, so that
. Also, the numerator is no larger than the denominator, so that  . Finally, we notice that
. Finally, we notice that .
.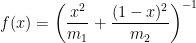 ,
, on the interval
on the interval  . Since
. Since ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , the absolute extrema can be found by checking the endpoints and the critical point(s).
, the absolute extrema can be found by checking the endpoints and the critical point(s).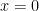 , then
, then  . On the other hand, if
. On the other hand, if  , then
, then  .
.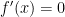 :
:![f'(x) = -\left( \displaystyle \frac{x^2}{m_1} + \frac{(1-x)^2}{m_2} \right)^{-2} \left[ \displaystyle \frac{2x}{m_1} - \frac{2(1-x)}{m_2} \right] = 0](https://s0.wp.com/latex.php?latex=f%27%28x%29+%3D+-%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7Bx%5E2%7D%7Bm_1%7D+%2B+%5Cfrac%7B%281-x%29%5E2%7D%7Bm_2%7D+%5Cright%29%5E%7B-2%7D+%5Cleft%5B+%5Cdisplaystyle+%5Cfrac%7B2x%7D%7Bm_1%7D+-+%5Cfrac%7B2%281-x%29%7D%7Bm_2%7D+%5Cright%5D+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002)

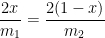
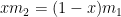



![f \left( \displaystyle \frac{m_1}{m_1+m_2} \right) = \left( \displaystyle \frac{1}{m_1} \frac{m_1^2}{(m_1+m_2)^2} + \frac{1}{m_2} \left[1-\frac{m_1}{m_1+m_2}\right]^2 \right)^{-1}](https://s0.wp.com/latex.php?latex=f+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7Bm_1%7D%7Bm_1%2Bm_2%7D+%5Cright%29+%3D+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bm_1%7D+%5Cfrac%7Bm_1%5E2%7D%7B%28m_1%2Bm_2%29%5E2%7D+%2B+%5Cfrac%7B1%7D%7Bm_2%7D+%5Cleft%5B1-%5Cfrac%7Bm_1%7D%7Bm_1%2Bm_2%7D%5Cright%5D%5E2+%5Cright%29%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![f \left( \displaystyle \frac{m_1}{m_1+m_2} \right) = \left( \displaystyle \frac{1}{m_1} \frac{m_1^2}{(m_1+m_2)^2} + \frac{1}{m_2} \left[\frac{m_2}{m_1+m_2}\right]^2 \right)^{-1}](https://s0.wp.com/latex.php?latex=f+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7Bm_1%7D%7Bm_1%2Bm_2%7D+%5Cright%29+%3D+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bm_1%7D+%5Cfrac%7Bm_1%5E2%7D%7B%28m_1%2Bm_2%29%5E2%7D+%2B+%5Cfrac%7B1%7D%7Bm_2%7D+%5Cleft%5B%5Cfrac%7Bm_2%7D%7Bm_1%2Bm_2%7D%5Cright%5D%5E2+%5Cright%29%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)



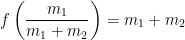
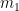 and
and  , while the absolute maximum is equal to
, while the absolute maximum is equal to  .
.
 is much smaller than
is much smaller than 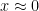 ), then
), then 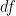 will be close to
will be close to  .
.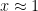 ), then
), then  , but no larger.
, but no larger.