When conducting an hypothesis test or computing a confidence interval for the difference 

rounded down to the nearest integer. In this formula, 
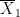


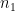

The terms 
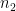

In Welch’s formula, the term 


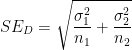
This leads to the “Pythagorean” relationship

which (in my experience) is a reasonable aid to help students remember the formula for

Naturally, a big problem that students encounter when using Welch’s formula is that the formula is really, really complicated, and it’s easy to make a mistake when entering information into their calculators. (Indeed, it might be that the pre-programmed calculator function simply gives the wrong answer.) Also, since the formula is complicated, students don’t have a lot of psychological reassurance that, when they come out the other end, their answer is actually correct. So, when teaching this topic, I tell my students the following rule of thumb so that they can at least check if their final answer is plausible:
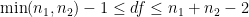
To my surprise, I have never seen this formula in a statistics textbook, even though it’s quite simple to state and not too difficult to prove using techniques from first-semester calculus.
Let’s rewrite Welch’s formula as
![df = \left( \displaystyle \frac{1}{n_1-1} \left[ \frac{SE_1^2}{SE_1^2 + SE_2^2}\right]^2 + \frac{1}{n_2-1} \left[ \frac{SE_2^2}{SE_1^2 + SE_2^2} \right]^2 \right)^{-1}](https://s0.wp.com/latex.php?latex=df+%3D+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bn_1-1%7D+%5Cleft%5B+%5Cfrac%7BSE_1%5E2%7D%7BSE_1%5E2+%2B+SE_2%5E2%7D%5Cright%5D%5E2+%2B+%5Cfrac%7B1%7D%7Bn_2-1%7D+%5Cleft%5B+%5Cfrac%7BSE_2%5E2%7D%7BSE_1%5E2+%2B+SE_2%5E2%7D+%5Cright%5D%5E2+%5Cright%29%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
For the sake of simplicity, let 

![df = \left( \displaystyle \frac{1}{m_1} \left[ \frac{SE_1^2}{SE_1^2 + SE_2^2}\right]^2 + \frac{1}{m_2} \left[ \frac{SE_2^2}{SE_1^2 + SE_2^2} \right]^2 \right)^{-1}](https://s0.wp.com/latex.php?latex=df+%3D+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bm_1%7D+%5Cleft%5B+%5Cfrac%7BSE_1%5E2%7D%7BSE_1%5E2+%2B+SE_2%5E2%7D%5Cright%5D%5E2+%2B+%5Cfrac%7B1%7D%7Bm_2%7D+%5Cleft%5B+%5Cfrac%7BSE_2%5E2%7D%7BSE_1%5E2+%2B+SE_2%5E2%7D+%5Cright%5D%5E2+%5Cright%29%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Now let 
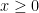


Using these observations, Welch’s formula reduces to the function
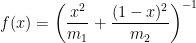
and the central problem is to find the maximum and minimum values of 

![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002)
First, the endpoints. If 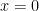



Next, the critical point(s). These are found by solving the equation 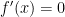
![f'(x) = -\left( \displaystyle \frac{x^2}{m_1} + \frac{(1-x)^2}{m_2} \right)^{-2} \left[ \displaystyle \frac{2x}{m_1} - \frac{2(1-x)}{m_2} \right] = 0](https://s0.wp.com/latex.php?latex=f%27%28x%29+%3D+-%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7Bx%5E2%7D%7Bm_1%7D+%2B+%5Cfrac%7B%281-x%29%5E2%7D%7Bm_2%7D+%5Cright%29%5E%7B-2%7D+%5Cleft%5B+%5Cdisplaystyle+%5Cfrac%7B2x%7D%7Bm_1%7D+-+%5Cfrac%7B2%281-x%29%7D%7Bm_2%7D+%5Cright%5D+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002)

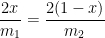
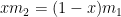



Plugging back into the original equation, we find the local extremum
![f \left( \displaystyle \frac{m_1}{m_1+m_2} \right) = \left( \displaystyle \frac{1}{m_1} \frac{m_1^2}{(m_1+m_2)^2} + \frac{1}{m_2} \left[1-\frac{m_1}{m_1+m_2}\right]^2 \right)^{-1}](https://s0.wp.com/latex.php?latex=f+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7Bm_1%7D%7Bm_1%2Bm_2%7D+%5Cright%29+%3D+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bm_1%7D+%5Cfrac%7Bm_1%5E2%7D%7B%28m_1%2Bm_2%29%5E2%7D+%2B+%5Cfrac%7B1%7D%7Bm_2%7D+%5Cleft%5B1-%5Cfrac%7Bm_1%7D%7Bm_1%2Bm_2%7D%5Cright%5D%5E2+%5Cright%29%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![f \left( \displaystyle \frac{m_1}{m_1+m_2} \right) = \left( \displaystyle \frac{1}{m_1} \frac{m_1^2}{(m_1+m_2)^2} + \frac{1}{m_2} \left[\frac{m_2}{m_1+m_2}\right]^2 \right)^{-1}](https://s0.wp.com/latex.php?latex=f+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7Bm_1%7D%7Bm_1%2Bm_2%7D+%5Cright%29+%3D+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bm_1%7D+%5Cfrac%7Bm_1%5E2%7D%7B%28m_1%2Bm_2%29%5E2%7D+%2B+%5Cfrac%7B1%7D%7Bm_2%7D+%5Cleft%5B%5Cfrac%7Bm_2%7D%7Bm_1%2Bm_2%7D%5Cright%5D%5E2+%5Cright%29%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)



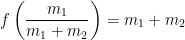
Based on the three local extrema that we’ve found, it’s clear that the absolute minimum of 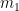



In conclusion, I suggest offering the following guidelines to students to encourage their intuition about the plausibility of their answers:
- If
is much smaller than
), then
will be close to
.
- If
), then
- Otherwise,
, but no larger.

3 thoughts on “Welch’s formula”