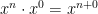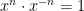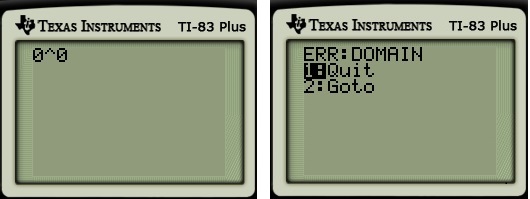
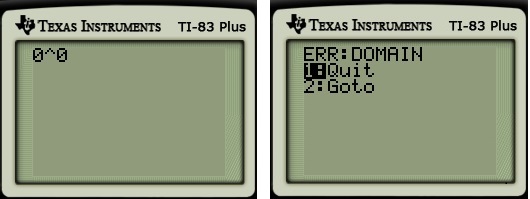
Here’s an explanation for why  is undefined that should be within the grasp of pre-algebra students:
is undefined that should be within the grasp of pre-algebra students:
Part 1.
- What is
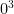 ? Of course, it’s
? Of course, it’s  .
.
- What is
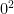 ? Again, .
? Again, .
- What is
 ? Again, .
? Again, .
- What is
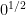 , or
, or 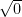 ? Again, .
? Again, .
- What is
 , or
, or ![\sqrt[3]{0}](https://s0.wp.com/latex.php?latex=%5Csqrt%5B3%5D%7B0%7D&bg=ffffff&fg=000000&s=0&c=20201002) ? In other words, what number, when cubed, is ? Again, .
? In other words, what number, when cubed, is ? Again, .
- What is
 , or
, or ![\sqrt[10]{0}](https://s0.wp.com/latex.php?latex=%5Csqrt%5B10%5D%7B0%7D&bg=ffffff&fg=000000&s=0&c=20201002) ? In other words, what number, when raised to the 10th power, is . Again, .
? In other words, what number, when raised to the 10th power, is . Again, .
So as the exponent gets closer to , the answer remains . So, from this perspective, it looks like ought to be equal to .
Part 2.
- What is
 . Of course, it’s
. Of course, it’s  .
.
- What is
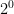 . Again, .
. Again, .
- What is
 . Again, .
. Again, .
- What is
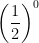 ? Again,
? Again,
- What is
 . Again,
. Again,
- What is
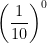 ? Again,
? Again,
So as the base gets closer to , the answer remains . So, from this perspective, it looks like ought to be equal to .
In conclusion: looking at it one way, should be defined to be . From another perspective, should be defined to be .
Of course, we can’t define a number to be two different things! So we’ll just say that is undefined — just like dividing by is undefined — rather than pretend that switches between two different values.

Here’s a more technical explanation about why is an indeterminate form, using calculus.
Part 1. As before,
 .
.
The first equality is true because, inside of the limit,  is permitted to get close to but cannot actually equal , and there’s no ambiguity about
is permitted to get close to but cannot actually equal , and there’s no ambiguity about 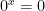 if
if 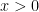 . (Naturally,
. (Naturally,  is undefined if
is undefined if 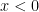 .)
.)
The second equality is true because the limit of a constant is the constant.
Part 2. As before,
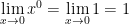 .
.
Once again, the first equality is true because, inside of the limit, is permitted to get close to but cannot actually equal , and there’s no ambiguity about  if
if 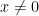 .
.
As before, the answers from Parts 1 and 2 are different. But wait, there’s more…
Part 3. Here’s another way that can be considered, just to give us a headache. Let’s evaluate

Clearly, the base tends to as  . Also,
. Also,  as
as 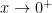 , so that
, so that  as . In other words, this limit has the indeterminate form .
as . In other words, this limit has the indeterminate form .
To evaluate this limit, let’s take a logarithm under the limit:



Therefore, without the extra logarithm,
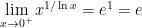
Part 4. It gets even better. Let  be any positive real number. By the same logic as above,
be any positive real number. By the same logic as above,
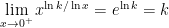
So, for any 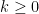 , we can find a function
, we can find a function  of the indeterminate form so that
of the indeterminate form so that  .
.
In other words, we could justify defining to be any nonnegative number. Clearly, it’s better instead to simply say that is undefined.
P.S. I don’t know if it’s possible to have an indeterminate form of where the answer is either negative or infinite. I tend to doubt it, but I’m not sure.
 th derivative of the original function, and higher-order derivatives usually get progressively messier with each successive differentiation.
th derivative of the original function, and higher-order derivatives usually get progressively messier with each successive differentiation. ,
,  ,
, 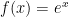 , and
, and  .
. .
.  messier and messier, but
messier and messier, but 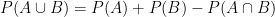
 or
or  happens is the probability of event
happens is the probability of event  .
.

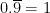 . Here’s the idea: how far apart are the two numbers?
. Here’s the idea: how far apart are the two numbers?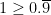 , we know that
, we know that  .
.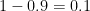 . Since
. Since 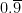 must lie between
must lie between  and
and  must be less than
must be less than  .
.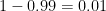 . Since
. Since 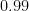 and
and 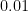 .
. . Since
. Since 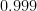 and
and  .
.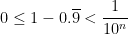
 ? Clearly, the only such number is
? Clearly, the only such number is 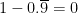 , or
, or 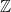 and real numbers
and real numbers 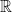 . For integers, there is always an integer to the immediate left and to the immediate right. In other words, if you give me any integer (say,
. For integers, there is always an integer to the immediate left and to the immediate right. In other words, if you give me any integer (say,  ), I can tell you the largest integer that’s less than your number (in our example,
), I can tell you the largest integer that’s less than your number (in our example, 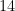 ) and the smallest integer that’s bigger than your number (
) and the smallest integer that’s bigger than your number ( ).
). is the real number to the immediate left of
is the real number to the immediate left of  is bigger than
is bigger than  — there is no number to the immediate left of
— there is no number to the immediate left of  and that, more generally, a real number may have more than one decimal representation even though a decimal representation corresponds to only one real number. This can be a major conceptual barrier for even bright students to overcome. I have met a few math majors within a semester of graduating — that is, they weren’t dummies — who could recite all of these ways and were perhaps logically convinced but remained psychologically unconvinced.
and that, more generally, a real number may have more than one decimal representation even though a decimal representation corresponds to only one real number. This can be a major conceptual barrier for even bright students to overcome. I have met a few math majors within a semester of graduating — that is, they weren’t dummies — who could recite all of these ways and were perhaps logically convinced but remained psychologically unconvinced. and
and  . Then the midpoint of
. Then the midpoint of 

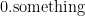 Furthermore, the midpoint does not equal
Furthermore, the midpoint does not equal  . In other words, the midpoint has to have one of the following 9 forms:
. In other words, the midpoint has to have one of the following 9 forms:



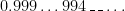



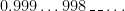

 , and the common ratio needed to go from one term to the next term is
, and the common ratio needed to go from one term to the next term is 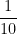 . Therefore,
. Therefore,

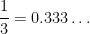
 :
:


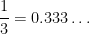 and
and 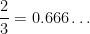
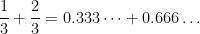

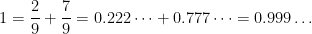

 and
and  or finding an
or finding an 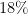 tip on a restaurant bill using only Roman numerals.)
tip on a restaurant bill using only Roman numerals.) and
and  ), then they ought to be different.
), then they ought to be different.![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) be the set of real numbers from
be the set of real numbers from  be the set of decimal representations of the form
be the set of decimal representations of the form  . Then there’s clearly a function
. Then there’s clearly a function  , defined by
, defined by
 , and the formula for an
, and the formula for an  maps
maps 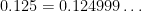
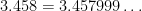
 . Multiply
. Multiply 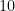 , and subtract:
, and subtract: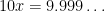


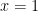
 . Of course, he knew that these rules were true and he could apply them in complex problems, but he didn’t know why they were true. And he wanted to have this deeper knowledge of mathematics beyond the ability to solve routine algebra problems.
. Of course, he knew that these rules were true and he could apply them in complex problems, but he didn’t know why they were true. And he wanted to have this deeper knowledge of mathematics beyond the ability to solve routine algebra problems.
 , this can be proven by repeated multiplication:
, this can be proven by repeated multiplication: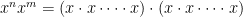 repeated
repeated  repeated
repeated 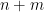 times
times and
and 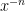 should be defined so that this rule still holds even if one (or both) of
should be defined so that this rule still holds even if one (or both) of