In this series of posts, I provide a deeper look at common applications of exponential functions that arise in an Algebra II or Precalculus class. In the previous posts in this series, I considered financial applications, radioactive decay, and Newton’s Law of Cooling.
Today, I introduce the logistic growth model, which describes how an infection (like a disease, a rumor, or advertise) spreads in a population. Before I actually present the formula to my students, I usually perform a 8- to 10-minute demonstration to convince students that the formula actually works. This demonstration works well with between 15 and 45 students; I have personally not attempted this demo with a class larger than 45.
I wish I could take credit for the idea behind this demonstration. I’m afraid I can’t remember who told me the idea behind this demo about 15 years ago, but I’m thankful to him or her for this idea, as I’ve used it with great success over the years when teaching Precalculus and even when teaching Differential Equations.
Here’s the demonstration:
1. The class period before the demo, I ask my students to bring their calculators to class.
2. On the day of the demo, I prepare slips of paper with the numbers 1, 2, 3, etc. I hand these to my students as they take their seats before class starts (and, as needed, to students who arrive late).
3. I tell the class that we’re going to model how a rumor gets spread. On the chalkboard, I write down the numbers 0, 1, 2, …, up to  , the number of students in the class that day. Invariably, I get asked, “What’s the rumor?” In response, I’ll playfully point to someone in the front row and say, “The rumor is about him.”
, the number of students in the class that day. Invariably, I get asked, “What’s the rumor?” In response, I’ll playfully point to someone in the front row and say, “The rumor is about him.”
4. I point out that, at time 0, only one person has heard the rumor…. me. I’m person number 0 (confirming the popular belief of my students). So I’ll cross out the 0 on the board and mark on a table that only one person has heard the rumor so far. (Here’s the spreadsheet that I’ve used to keep track of this information while simultaneously making a graph of the data: logisitic).
5. I begin to spread the rumor. To spread the rumor, I use my calculator to get a random number between  and . This can be done by just using the built-in random number generator found on many calculators and then multiplying by
and . This can be done by just using the built-in random number generator found on many calculators and then multiplying by  . (After all, there are
. (After all, there are 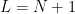 people in the room: students plus one instructor.) The part after the decimal point is not important; the number before the decimal point represents the next person to hear the rumor.
people in the room: students plus one instructor.) The part after the decimal point is not important; the number before the decimal point represents the next person to hear the rumor.
For example, in the figure below, I would tell that person #35 of my class of 37 students was the next to hear the rumor. (If my random number is 0, I’ll privately cheat and get until I get a random number other than 0. I only permit the possibility of cheating on the first step so that the data fits the predicted curve as accurately as possible.)
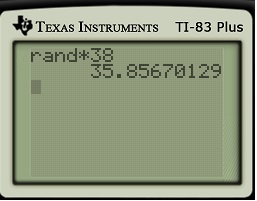 6. At this point, I’ll X out the number of the next person to hear the rumor (in this case, 35), and I then ask how many people have heard the rumor. Obviously, two people have heard the rumor. So I’ll note on the table that two people have heard the rumor after one step.
6. At this point, I’ll X out the number of the next person to hear the rumor (in this case, 35), and I then ask how many people have heard the rumor. Obviously, two people have heard the rumor. So I’ll note on the table that two people have heard the rumor after one step.
7. Now we repeat the process. I get a new random number, and I ask the first student to pull out his/her calculator to get a random number too. But there’s an important rule: if you get a number that’s already been called, that’s OK. This models what really happens when a rumor (or disease) spreads in a population — it’s perfectly possible to hear the rumor twice.
8. We repeat the process — X’ing out numbers that have been previously called and students calling out the next person to hear the rumor — until the entire class hears the rumor. At some point, it becomes easiest to ask students to only call out if they get a number that hasn’t been called yet. Invariably, there’s always one person at the end who hasn’t heard the rumor yet, and this student is often the subject of some good-natured ribbing. Eventually, a chart like the following is produced.

9. Students immediately see that this is a different type of function than pure exponential growth. It actually does start off looking like exponential growth, but at some point the curve levels off. This makes sense because there’s a limiting value of  (in this case, 38), which can’t happen for a model like
(in this case, 38), which can’t happen for a model like 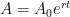
10. The punchline is that the spreadsheet secretly computes the actual curve predicted by the logistic growth model. The numbers are actually located in column C, which is conveniently hidden beneath the graph. The function is
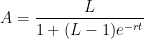 ,
,
where 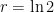 . (Had each person the rumor to two different people at each step, then
. (Had each person the rumor to two different people at each step, then  would have been equal to
would have been equal to  .) Here’s the graph, superimposed upon the data collected from class. I can do this pretty quickly in class because the curve is actually already drawn in the figure above… but it’s drawn in gray, the same color as the background. By changing the color to black, the graph becomes clear:
.) Here’s the graph, superimposed upon the data collected from class. I can do this pretty quickly in class because the curve is actually already drawn in the figure above… but it’s drawn in gray, the same color as the background. By changing the color to black, the graph becomes clear:

I never expect the curve to exactly fit the data, but it should come pretty close. After this fairly dramatic revelation, my students are completely sold that the mathematics that I’m about to show them actually works.
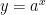

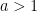

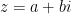


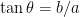



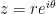

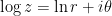
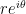


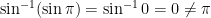
![\log \left[ (-1) \cdot (-1) \right] = \log 1 = 0](https://s0.wp.com/latex.php?latex=%5Clog+%5Cleft%5B+%28-1%29+%5Ccdot+%28-1%29+%5Cright%5D+%3D+%5Clog+1+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002)
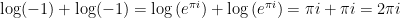

 .
. .
.

 between
between  and
and  so that
so that  . This can happen in two ways.
. This can happen in two ways. or else
or else  . Students can visualize this by drawing a picture, talking through each step of its construction (first black, then red, then brown, then green, then blue).
. Students can visualize this by drawing a picture, talking through each step of its construction (first black, then red, then brown, then green, then blue).

 and $126.9 + 360n^{\circ}$, where
and $126.9 + 360n^{\circ}$, where  is an integer. Since integers can be negative, there’s no need to write
is an integer. Since integers can be negative, there’s no need to write  in the solution.
in the solution.
 .
. intercept:
intercept: .
.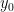 represents the initial number of people who have the infection.
represents the initial number of people who have the infection. gets large:
gets large: .
. people will get the infection eventually. (Of course, Precalculus students won’t be familiar with the $\displaystyle \lim$ notation, but they should understand that
people will get the infection eventually. (Of course, Precalculus students won’t be familiar with the $\displaystyle \lim$ notation, but they should understand that  decays to zero as
decays to zero as  above, it would be a somewhat daunting exercise!
above, it would be a somewhat daunting exercise!![A' = r A [ L - A] = r L A - r A^2](https://s0.wp.com/latex.php?latex=A%27+%3D+r+A+%5B+L+-+A%5D+%3D+r+L+A+-+r+A%5E2&bg=ffffff&fg=000000&s=0&c=20201002)
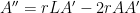

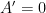 or else
or else  . The first case corresponds to the trivial cases
. The first case corresponds to the trivial cases  and
and  ; these constants are called the equilibrium solutions. The second case is the more interesting one:
; these constants are called the equilibrium solutions. The second case is the more interesting one:
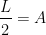
 and solving for
and solving for 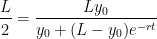 .
.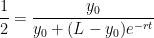 .
.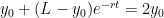



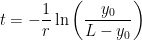

 .
.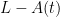 is the number of people who don’t have the disease. Therefore, the product
is the number of people who don’t have the disease. Therefore, the product ![A(t) [ L - A(t) ]](https://s0.wp.com/latex.php?latex=A%28t%29+%5B+L+-+A%28t%29+%5D+&bg=ffffff&fg=000000&s=0&c=20201002) is the number of possible contacts between those who have the disease and those who don’t. This leads to the governing differential equation
is the number of possible contacts between those who have the disease and those who don’t. This leads to the governing differential equation![A'(t) = c A(t) [ L - A(t) ]](https://s0.wp.com/latex.php?latex=A%27%28t%29+%3D+c+A%28t%29+%5B+L+-+A%28t%29+%5D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, is the constant of proportionality. This is often rewritten by letting
is the constant of proportionality. This is often rewritten by letting  , or
, or  :
:![A'(t) = \displaystyle \frac{r}{L} A(t) [ L - A(t) ]](https://s0.wp.com/latex.php?latex=A%27%28t%29+%3D+%5Cdisplaystyle+%5Cfrac%7Br%7D%7BL%7D+A%28t%29+%5B+L+-+A%28t%29+%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![A'(t) = r A(t) \displaystyle \left[1 - \frac{A(t)}{L} \right]](https://s0.wp.com/latex.php?latex=A%27%28t%29+%3D+r+A%28t%29+%5Cdisplaystyle+%5Cleft%5B1+-+%5Cfrac%7BA%28t%29%7D%7BL%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 , which makes this differential equation non-linear.
, which makes this differential equation non-linear.


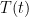 of the object is found to be
of the object is found to be ,
, is the constant surrounding temperature, and
is the constant surrounding temperature, and  is a constant that depends on the object.
is a constant that depends on the object. as a function of time, use linear regression to solve for the constant
as a function of time, use linear regression to solve for the constant 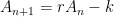
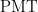 :
:
![M = \displaystyle \frac{Pr}{12 \displaystyle \left[1 - \left( 1 + \frac{r}{12} \right)^{-12t} \right]}](https://s0.wp.com/latex.php?latex=M+%3D+%5Cdisplaystyle+%5Cfrac%7BPr%7D%7B12+%5Cdisplaystyle+%5Cleft%5B1+-+%5Cleft%28+1+%2B+%5Cfrac%7Br%7D%7B12%7D+%5Cright%29%5E%7B-12t%7D+%5Cright%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
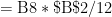
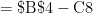
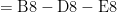
 . However, in the long run, those payments saved about
. However, in the long run, those payments saved about  !
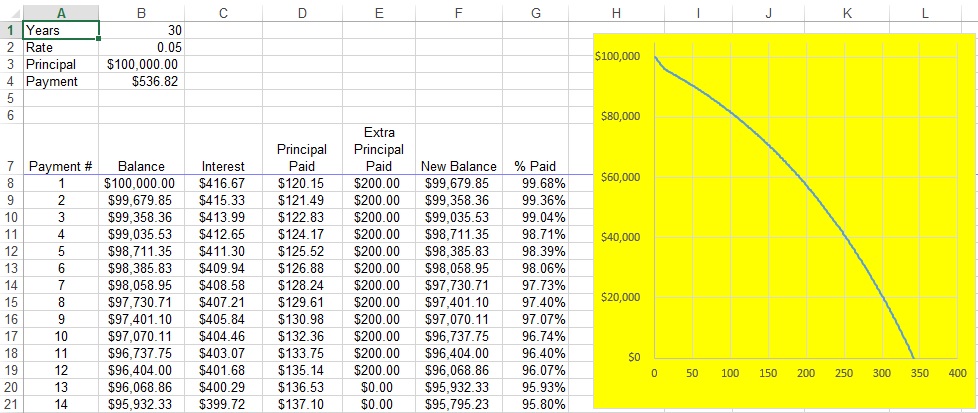
!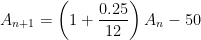

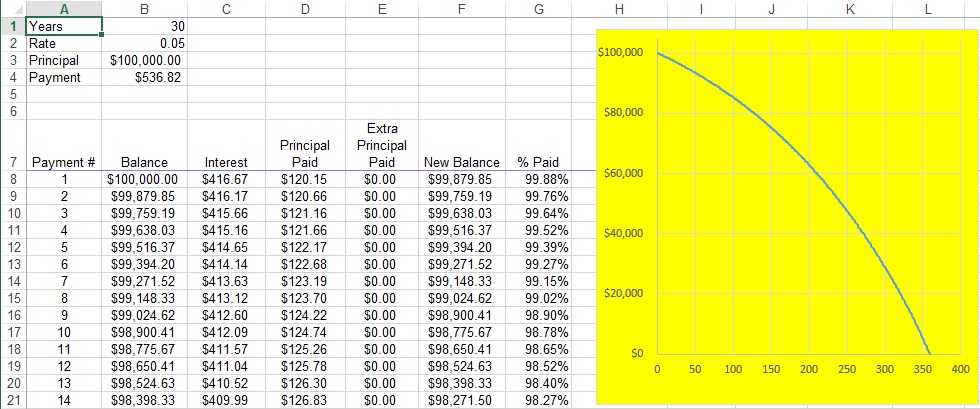
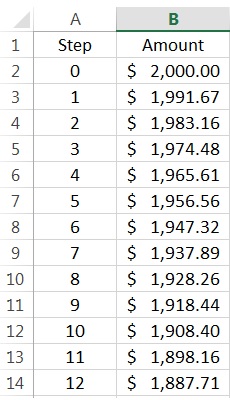
 in Cell B2. (In the screenshot below, I changed the format of column B to show dollars and cents.) Next, I entered
in Cell B2. (In the screenshot below, I changed the format of column B to show dollars and cents.) Next, I entered  in Cell A3 and
in Cell A3 and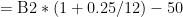


 can be thought about in three different ways.
can be thought about in three different ways. .
. 2. We have the limits
2. We have the limits .
. . From this derivative,
. From this derivative, 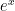 about
about  can be computed:
can be computed:
 to find
to find 
 gives a somewhat more tractable way of approximating
gives a somewhat more tractable way of approximating 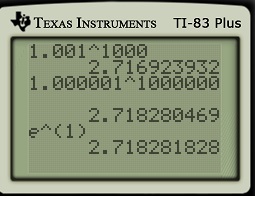
 get very small very quickly, leading to rapid convergence. Indeed, with only terms up to
get very small very quickly, leading to rapid convergence. Indeed, with only terms up to  , this approximation beats the above approximation with
, this approximation beats the above approximation with 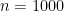 . Adding just two extra terms comes close to matching the accuracy of the above limit when
. Adding just two extra terms comes close to matching the accuracy of the above limit when  .
.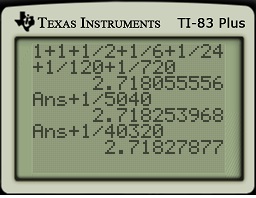
![[1,1.8]](https://s0.wp.com/latex.php?latex=%5B1%2C1.8%5D&bg=ffffff&fg=000000&s=0&c=20201002) and
and ![[1.8,2.6]](https://s0.wp.com/latex.php?latex=%5B1.8%2C2.6%5D&bg=ffffff&fg=000000&s=0&c=20201002) . (Because I need a good picture, I used Mathematica and not Microsoft Paint.)
. (Because I need a good picture, I used Mathematica and not Microsoft Paint.)
 . Furthermore, the bases of the first trapezoids have length
. Furthermore, the bases of the first trapezoids have length  and
and  , while the bases of the second trapezoid of length
, while the bases of the second trapezoid of length 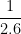 . Notice that the trapezoids extend above the hyperbola, so that
. Notice that the trapezoids extend above the hyperbola, so that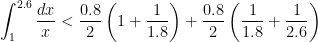

 , and so
, and so
 is strictly less than
is strictly less than  . Can we do better? Sadly, with two equal-sized trapezoids, we can’t do much better. If the height of the trapezoids was
. Can we do better? Sadly, with two equal-sized trapezoids, we can’t do much better. If the height of the trapezoids was  and not
and not 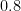 , then the sum of the areas of the two trapezoids would be
, then the sum of the areas of the two trapezoids would be
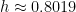 , thus establishing that
, thus establishing that  .
.
 .
.
 .
.
 ranging from
ranging from 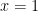 to
to  .
.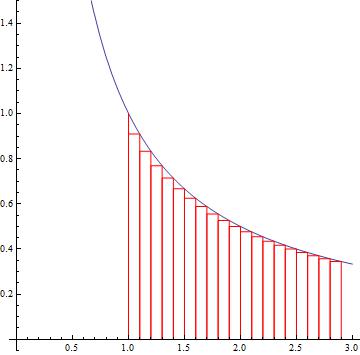
 to
to  . Therefore,
. Therefore,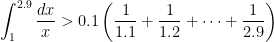

 is strictly greater than
is strictly greater than 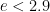 .
.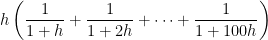

 . With 1000 rectangles, we can establish that
. With 1000 rectangles, we can establish that  .
. , but we’re not yet sure if the next digit is
, but we’re not yet sure if the next digit is  or
or  .
.