I’ve linked to a number of articles about the misuse of p-values. Recently, I read a nice article in the October/November 2019 issue of MAA Focus summarizing a conversation between the Executive Directors of the Mathematical Association of America and the American Statistical Association about the ASA’s call to eliminate the use of p-values. Per copyright, I can’t copy the entire article here, but let me quote the lead paragraph:
In March 2016, the American Statistical Association took the extraordinary step of issuing a Statement on p-Values and Statistical Significance. This spring, the association went even further, publishing a massive special issue of its journal The American Statistician entitled Statistical Inference in the 21st Century: A World Beyond p<0.05. The lead editorial in that special issue called for the end of the use of the concept of statistical significance.
It’s going to be a while before entrenched statistics textbooks catch up with this new standard of professional practice.
Here’s an NPR article on the issue: https://www.npr.org/sections/health-shots/2019/03/20/705191851/statisticians-call-to-arms-reject-significance-and-embrace-uncertainty
Other articles cited in the MAA Focus article:
- http://sciencealert.com/statisticians-argue-it-s-time-to-ditch-significance-in-science-and-replace-it-with-uncertainty
- http://psychologytoday.com/us/blog/the-athletes-way/201903/rethinking-p-values-is-statistical-significance-useless
- http://theness.com/neurologicablog/index.php/get-rid-of-statistical-significance
- http://sciencenews.org/article/statisticians-standard-measure-significance-p-values
- http://vox.com/latest-news/2019/3/22/18275913/statistical-significance-p-values-explained
 -value. For example:
-value. For example: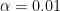 .
. and the
and the 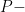 value is about
value is about  . After the computations, I’ll then discuss what the numbers mean.
. After the computations, I’ll then discuss what the numbers mean. is not a line that separates real results from false ones. They’re simply one piece of a puzzle that should be considered in the context of other evidence.
is not a line that separates real results from false ones. They’re simply one piece of a puzzle that should be considered in the context of other evidence.
