The classic application of confidence intervals is political polling: the science of sampling relatively few people to predict the opinions of a large population. However, in the 2010s, the art of political polling — constructing representative samples from a large population — has become more and more difficult. FiveThirtyEight.com had a nice feature about problems that pollsters face today that were not issues a generation ago. A sampling:
The problem is simple but daunting. The foundation of opinion research has historically been the ability to draw a random sample of the population. That’s become much harder to do, at least in the United States. Response rates to telephone surveys have been declining for years and are often in the single digits, even for the highest-quality polls. The relatively few people who respond to polls may not be representative of the majority who don’t. Last week, the Federal Communications Commission proposed new guidelines that could make telephone polling even harder by enabling phone companies to block calls placed by automated dialers, a tool used in almost all surveys.
What about Internet-based surveys? They’ll almost certainly be a big part of polling’s future. But there’s not a lot of agreement on the best practices for online surveys. It’s fundamentally challenging to “ping” a random voter on the Internet in the same way that you might by giving her an unsolicited call on her phone. Many pollsters that do Internet surveys eschew the concept of the random sample, instead recruiting panels that they claim are representative of the population.
Peer-reviewed publications is the best way that we’ve figured out for vetting scientific experiments and disseminating scientific knowledge. But that doesn’t mean that the system can’t be abused, either consciously or unconsciously.
Here’s a dirty little science secret: If you measure a large number of things about a small number of people, you are almost guaranteed to get a “statistically significant” result. Our study included 18 different measurements—weight, cholesterol, sodium, blood protein levels, sleep quality, well-being, etc.—from 15 people. (One subject was dropped.) That study design is a recipe for false positives.
Think of the measurements as lottery tickets. Each one has a small chance of paying off in the form of a “significant” result that we can spin a story around and sell to the media. The more tickets you buy, the more likely you are to win. We didn’t know exactly what would pan out—the headline could have been that chocolate improves sleep or lowers blood pressure—but we knew our chances of getting at least one “statistically significant” result were pretty good.
And:
With the paper out, it was time to make some noise. I called a friend of a friend who works in scientific PR. She walked me through some of the dirty tricks for grabbing headlines. It was eerie to hear the other side of something I experience every day.
The key is to exploit journalists’ incredible laziness. If you lay out the information just right, you can shape the story that emerges in the media almost like you were writing those stories yourself. In fact, that’s literally what you’re doing, since many reporters just copied and pasted our text.
And:
The only problem with the diet science beat is that it’s science. You have to know how to read a scientific paper—and actually bother to do it. For far too long, the people who cover this beat have treated it like gossip, echoing whatever they find in press releases. Hopefully our little experiment will make reporters and readers alike more skeptical.
If a study doesn’t even list how many people took part in it, or makes a bold diet claim that’s “statistically significant” but doesn’t say how big the effect size is, you should wonder why. But for the most part, we don’t. Which is a pity, because journalists are becoming the de facto peer review system. And when we fail, the world is awash in junk science.
Here are some of my favorite quotes from near the end of the article:
The key to decreasing p-hacking is better education of researchers. Many practices that lead to p-hacking are still deemed acceptable. John et al. measured the prevalence of questionable research practices in psychology. They asked survey participants if they had ever engaged in a set of questionable research practices and, if so, whether they thought their actions were defensible on a scale of 0–2 (0 = no, 1 = possibly, 2 = yes). Over 50% of participants admitted to “failing to report all of a study’s dependent measures” and “deciding whether to collect more data after looking to see whether the results were significant,” and these practices received a mean defensibility rating greater than 1.5. This indicates that many researchers p-hack but do not appreciate the extent to which this is a form of scientific misconduct. Amazingly, some animal ethics boards even encourage or mandate the termination of research if a significant result is obtained during the study, which is a particularly egregious form of p-hacking (Anonymous reviewer, personal communication).
Eliminating p-hacking entirely is unlikely when career advancement is assessed by publication output, and publication decisions are affected by the p-value or other measures of statistical support for relationships. Even so, there are a number of steps that the research community and scientific publishers can take to decrease the occurrence of p-hacking.
The Mathematical Association of America recently published a number of promotional videos showing various mathematics can be used in “the real world.” Here’s the fourth pair of videos describing how mathematics is used in the world of finance. From the YouTube descriptions:
Dr. Jonathan Adler (winner of King of the Nerds Season 3) talks about his career path and about a specific research problem that he has worked on. Using text analytics he was able to help an online company distinguish between its business customers and its private consumers from gift card messages.
Prof. Talithia Williams of Harvey Mudd College explains the statistical techniques that can be used to classify customers of a company using the messages on their gift cards.
In my capstone class for future secondary math teachers, I ask my students to come up with ideas for engaging their students with different topics in the secondary mathematics curriculum. In other words, the point of the assignment was not to devise a full-blown lesson plan on this topic. Instead, I asked my students to think about three different ways of getting their students interested in the topic in the first place.
I plan to share some of the best of these ideas on this blog (after asking my students’ permission, of course).
This student submission again comes from my former student Delaina Bazaldua. Her topic, from Algebra: approximating data to a straight line.
How has this topic appeared in pop culture (movies, TV, current music, video games, etc.)?
One of my favorite shows to watch is How I Met Your Mother. I specifically chose this topic for this class because of how it relates to an episode of the show. A piece of the episode that I’m referring to is shown in the YouTube video:
Barney, one of the main characters, describes the graph as the Crazy/Hot Scale. According to him, a girl cannot be crazier than hot which means she has to be above the diagonal straight line. This relates to the topic because one can approximate data by the straight line that Barney gives the viewer. I think the students will be able to relate to this and also find it humorous. Because this video has both of these characteristics, they will be able to remember the concept for upcoming homework and tests which is ultimately the most important part of math: understanding it and being able to recall it.
How has this topic appeared in the news?
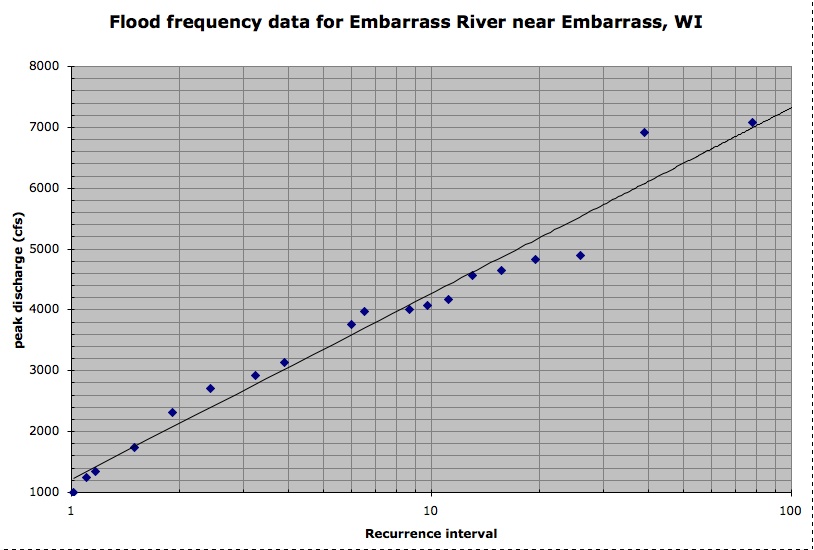
Most lines are drawn for the purpose of seeing if there is a relationship between the x and y axis and trying to figure out if you can approximate data from the straight line that is drawn. Graphs like this are found all over the news, and they often relate to natural disasters. For example, this linear regression, http://d32ogoqmya1dw8.cloudfront.net/images/quantskills/methods/quantlit/bestfit_line.v2.jpg, describes floods. In http://serc.carleton.edu/mathyouneed/graphing/bestfit.html, where the picture is found, describes more activities that can be used to create a linear regression which can be converted into a straight line. These examples of straight lines can be used to find more data that isn’t necessarily shown from the points that are plotted. The examples the website gave are: flood frequency curves, earthquake forecasting, meteorite impact prediction, earthquake frequency vs. magnitude, and climate change. This is beneficial for math because it allows students to realize that math isn’t abstract like it is often perceived to be, but rather, it is used for something very important and something that occurs several times a year such as natural disasters and weather.
How can this topic be used in your students’ future courses in mathematics or science?
One of the purposes for teachers to teach is for students to learn what they should for the following year so they can be successful in the particular topic. When it comes to approximating data based on a straight line, the knowledge a student learns in algebra will carry them through statistics, physics, and other higher math and science classes. Linear regression is shown in statistics as one can see in this statistics website: http://onlinestatbook.com/2/regression/intro.html while physics is represented in the physics website: http://dev.physicslab.org/Document.aspx?doctype=3&filename=IntroductoryMathematics_DataAnalysisMethods.xml. A lot can be predicted from these straight lines which is why these graphs aren’t foreign to upper level math and science classes. As I stated before, a lot can be predicted from the graph where data points aren’t necessarily on the trend the data is setting which allows students to expect what would occur at a particular x or y value. A background in this area can help students through the rest of school and perhaps even the rest of their life in some cases.
Most of our devout beliefs about nutrition have not been subjected to a robust, experimental, controlled clinical trial, the type of study that shows cause and effect, which may be why Americans are pummeled with contradictory and confounding nutritional advice.
To wit:
Many nutritional studies are observational studies, including massive ones like the Nurses’ Health Study. Researchers like Willett try to suss out how changes in diet affect health by looking at associations between what people report they eat and how long they live. When many observational studies reach the same conclusions, Willett says, there is enough evidence to support dietary recommendations. Even though they only show correlation, not cause and effect, observational studies direct what we eat.
Apart from their inability to determine cause and effect, there’s another problem with observational studies: The data they’re based on—surveys where people report what they ate the day (or week) before—are notoriously unreliable. Researchers have long known that people (even nurses) misreport, intentionally and unintentionally, what they eat. Scientists politely call this “recall bias.”
The coupling of observational studies and self-reported data leads some observers to the conclusion that we know neither how Americans do eat nor how they should eat. A recent PLOS One article even suggests that several national studies use data that is so wildly off base that the self-reported caloric intake is “incompatible with survival.” If people had eaten as little as they reported, in other words, they would be starving.
Peter Attia, a medical researcher and doctor, started questioning the basis of dietary guidelines when he saw that following them didn’t work for his patients. They didn’t lose weight, even when they virtuously stuck with their diets. When he took a look at the research supporting the advice he was giving to his patients, he saw shoddy science. Attia estimates that 16,000 nutritional studies are published each year, but the majority of them are deeply flawed: either poorly controlled clinical trials, observational studies, or animal studies. “Those studies wouldn’t pass muster in another field,” he told me.
This is a cute article about ways that people can lie with charts: (1) Puzzling perspective, (2) Swindling shapes, (3) Trendsetters are tricksters (implying a false correlation), (4) Hiding in plain sight, and (5) Changing the scale of the axis.
The classic application of confidence intervals is political polling: the science of sampling relatively few people to predict the opinions of a large population. However, in the 2010s, the art of political polling — constructing representative samples from a large population — has become more and more difficult.




{kind=link}