Sadly, at least at my university, Taylor series is the topic that is least retained by students years after taking Calculus II. They can remember the rules for integration and differentiation, but their command of Taylor series seems to slip through the cracks. In my opinion, the reason for this lack of retention is completely understandable from a student’s perspective: Taylor series is usually the last topic covered in a semester, and so students learn them quickly for the final and quickly forget about them as soon as the final is over.
Of course, when I need to use Taylor series in an advanced course but my students have completely forgotten this prerequisite knowledge, I have to get them up to speed as soon as possible. Here’s the sequence that I use to accomplish this task. Covering this sequence usually takes me about 30 minutes of class time.
I should emphasize that I present this sequence in an inquiry-based format: I ask leading questions of my students so that the answers of my students are driving the lecture. In other words, I don’t ask my students to simply take dictation. It’s a little hard to describe a question-and-answer format in a blog, but I’ll attempt to do this below.
In the previous posts, I described how I lead students to the definition of the Maclaurin series

which converges to 

Step 5. That was easy; let’s try another one. Now let’s try 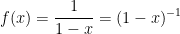
What’s 

Next, to find 

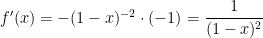

Next, we differentiate again: 

Hmmm… no obvious pattern yet… so let’s keep going.
For the next term, 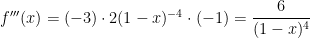

For the next term, 
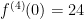
Oohh… it’s the factorials again! It looks like 
Plugging into the series, we find that

Like the series for 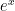
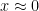

The right-hand side is a special kind of series typically discussed in precalculus. (Students often pause at this point, because most of them have forgotten this too.) It is an infinite geometric series whose first term is $1$ and common ratio $x$. So starting from the right-hand side, one can obtain the left-hand side using the formula

by letting 
In other words, in precalculus, we start with the geometric series and end with the function. With Taylor series, we start with the function and end with the series.
Step 6. A whole bunch of other Taylor series can be quickly obtained from the one for 

and

we have

____________________
Next, let’s replace 
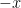

Now let’s take the indefinite integral of both sides:


To solve for the constant of integration, let 

Plugging back in, we conclude that

The Taylor series expansion for 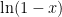

Subtracting, we find

My understanding is that this latter series is used by calculators when computing logarithms.
____________________
Next, let’s replace 
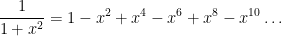
Now let’s take the indefinite integral of both sides:
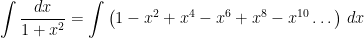
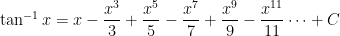
To solve for the constant of integration, let

Plugging back in, we conclude that

____________________
In summary, a whole bunch of Taylor series can be extracted quite quickly by differentiating and integrating from a simple infinite geometric series. I’m a firm believer in minimizing the number of formulas that I should memorize. Any time I personally need any of the above series, I’ll quickly use the above steps to derive them from that of
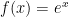 .
.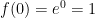 .
. . So
. So  .
. ? Yep, it’s also
? Yep, it’s also  for all
for all  , though we’ll skip the formal proof by induction.
, though we’ll skip the formal proof by induction.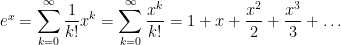
 . In other words, the series on the right converges for all values of
. In other words, the series on the right converges for all values of  notation still doesn’t have much meaning.
notation still doesn’t have much meaning.
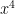 term and that about ten or eleven terms are needed to get a figure that is as accurate as the
term and that about ten or eleven terms are needed to get a figure that is as accurate as the 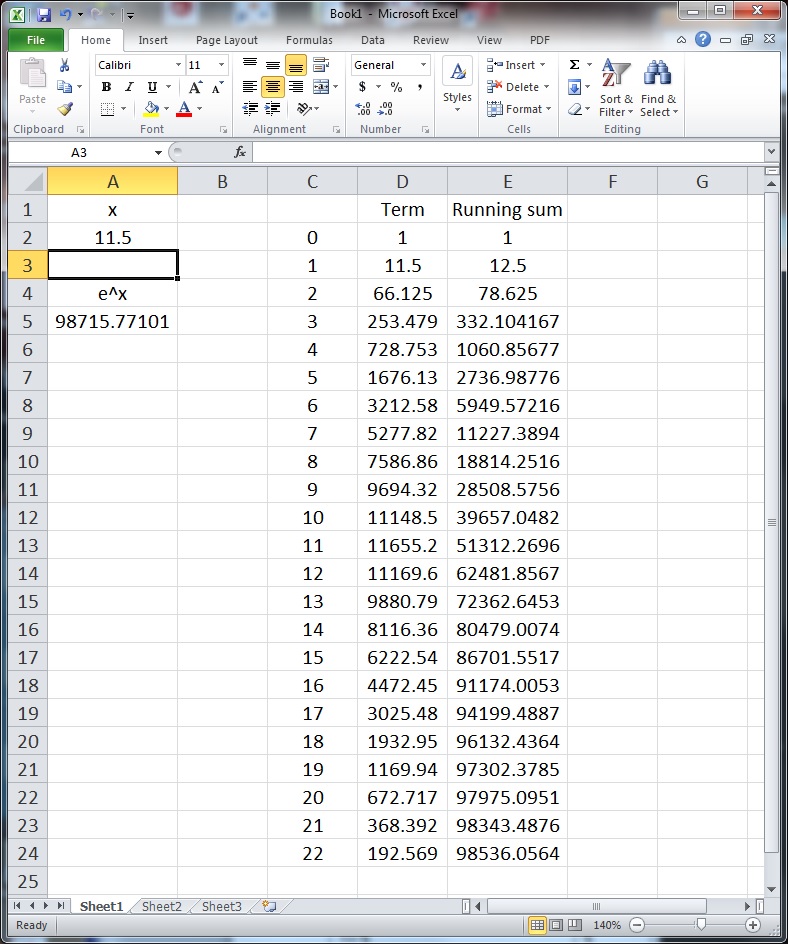
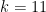 and then start getting smaller. I’ll ask my students why this happens, and I’ll eventually get an explanation like
and then start getting smaller. I’ll ask my students why this happens, and I’ll eventually get an explanation like

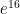 ,
, 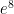 ,
,  ,
,  , and
, and  . I then ask my class how these could be used to find
. I then ask my class how these could be used to find  . After some thought, they will volunteer that
. After some thought, they will volunteer that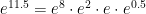 .
. , the series for
, the series for 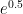 will converge pretty quickly. (Some students may volunteer that the above product is logically equivalent to turning
will converge pretty quickly. (Some students may volunteer that the above product is logically equivalent to turning  into binary.)
into binary.) .
. ,
, can be any number.
can be any number. .
. .
. .
.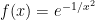 , which is so “flat” near $x=0$ that every single derivative of
, which is so “flat” near $x=0$ that every single derivative of  at
at  .
.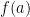 is the
is the 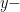 coordinate at
coordinate at 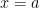 .
. is the slope of the curve at
is the slope of the curve at  is a measure of the concavity of the curve at — you guessed it —
is a measure of the concavity of the curve at — you guessed it — 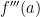 is an even more subtle description of the curve… once again, at
is an even more subtle description of the curve… once again, at  ,
,  ,
,  ,
, 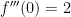 , and
, and  .
. , and start differentiating. Remember that
, and start differentiating. Remember that  ,
,  ,
,  , and
, and  are constants.
are constants.
 . Therefore, it must be that
. Therefore, it must be that 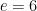 .
.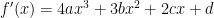 , and so
, and so  . Since
. Since  .
.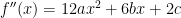 , and so
, and so  . Since
. Since 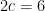 , or
, or 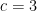 .
. , and so
, and so  . Since
. Since  , or
, or 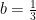 .
. , and so
, and so  . Since
. Since  , or
, or  .
. .
.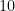 by
by  . Where did the
. Where did the  , and so
, and so .
. by
by 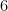 . The number
. The number 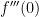 , and so
, and so .
.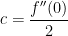 .
.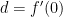 and
and 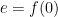 .
. and
and  .
.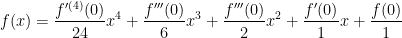 .
. term has a coefficient involving the third derivative of
term has a coefficient involving the third derivative of 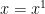 and the last term is multiplied by
and the last term is multiplied by  .
. where have we seen those before? Oh yes, the
where have we seen those before? Oh yes, the  ,
,  ,
,  ,
,  , and
, and  is defined to be
is defined to be 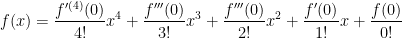 .
. notation:
notation: .
.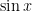 are used over and over again in higher mathematics.
are used over and over again in higher mathematics. A good working knowledge of Taylor series is necessary for computing series solutions of ordinary differential equations.
A good working knowledge of Taylor series is necessary for computing series solutions of ordinary differential equations. are used over and over again. For example, the
are used over and over again. For example, the 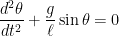 ,
, is the acceleration due to gravity and
is the acceleration due to gravity and 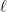 is the length of the pendulum. This differential equation cannot be solved exactly, and its solution is
is the length of the pendulum. This differential equation cannot be solved exactly, and its solution is  , so that the differential equation becomes
, so that the differential equation becomes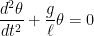 ,
,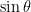 term, we now have a second-order differential equation with constant coefficients, which can be solved in a straightforward manner using standard techniques from differential equations. If
term, we now have a second-order differential equation with constant coefficients, which can be solved in a straightforward manner using standard techniques from differential equations. If 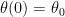 and
and 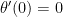 (i.e., the pendulum is pulled a small angle
(i.e., the pendulum is pulled a small angle 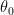 and is then released), the solution is
and is then released), the solution is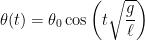 .
. , it doesn’t draw a unit circle, trace out an angle of
, it doesn’t draw a unit circle, trace out an angle of  in standard position, and find the
in standard position, and find the  coordinate of the terminal point. Instead, the calculator converts
coordinate of the terminal point. Instead, the calculator converts 
 , and (as I’ll discuss) the Maclaurin series for
, and (as I’ll discuss) the Maclaurin series for  converges much faster than the Maclaurin series for
converges much faster than the Maclaurin series for  at
at  .
. of two means, where at least one mean does not arise from a small sample, the Student t distribution must be employed. In particular, the number of degrees of freedom for the Student t distribution must be computed. Many textbooks suggest using
of two means, where at least one mean does not arise from a small sample, the Student t distribution must be employed. In particular, the number of degrees of freedom for the Student t distribution must be computed. Many textbooks suggest using 
 is the standard error associated with the first average
is the standard error associated with the first average 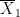 , where
, where  (if known) is the population standard deviation for
(if known) is the population standard deviation for  and
and 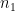 is the number of samples that are averaged to find
is the number of samples that are averaged to find  is employed.
is employed. and
and 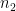 are similarly defined for the average
are similarly defined for the average  .
. in the numerator is equal to
in the numerator is equal to  . This is the square of the standard error
. This is the square of the standard error  associated with the difference
associated with the difference 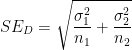 .
. ,
,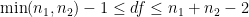 .
.![df = \left( \displaystyle \frac{1}{n_1-1} \left[ \frac{SE_1^2}{SE_1^2 + SE_2^2}\right]^2 + \frac{1}{n_2-1} \left[ \frac{SE_2^2}{SE_1^2 + SE_2^2} \right]^2 \right)^{-1}](https://s0.wp.com/latex.php?latex=df+%3D+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bn_1-1%7D+%5Cleft%5B+%5Cfrac%7BSE_1%5E2%7D%7BSE_1%5E2+%2B+SE_2%5E2%7D%5Cright%5D%5E2+%2B+%5Cfrac%7B1%7D%7Bn_2-1%7D+%5Cleft%5B+%5Cfrac%7BSE_2%5E2%7D%7BSE_1%5E2+%2B+SE_2%5E2%7D+%5Cright%5D%5E2+%5Cright%29%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 and
and  , so that
, so that![df = \left( \displaystyle \frac{1}{m_1} \left[ \frac{SE_1^2}{SE_1^2 + SE_2^2}\right]^2 + \frac{1}{m_2} \left[ \frac{SE_2^2}{SE_1^2 + SE_2^2} \right]^2 \right)^{-1}](https://s0.wp.com/latex.php?latex=df+%3D+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bm_1%7D+%5Cleft%5B+%5Cfrac%7BSE_1%5E2%7D%7BSE_1%5E2+%2B+SE_2%5E2%7D%5Cright%5D%5E2+%2B+%5Cfrac%7B1%7D%7Bm_2%7D+%5Cleft%5B+%5Cfrac%7BSE_2%5E2%7D%7BSE_1%5E2+%2B+SE_2%5E2%7D+%5Cright%5D%5E2+%5Cright%29%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 . All of these terms are nonnegative (and, in practice, they’re all positive), so that
. All of these terms are nonnegative (and, in practice, they’re all positive), so that  . Also, the numerator is no larger than the denominator, so that
. Also, the numerator is no larger than the denominator, so that  . Finally, we notice that
. Finally, we notice that .
. ,
, . Since
. Since ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , the absolute extrema can be found by checking the endpoints and the critical point(s).
, the absolute extrema can be found by checking the endpoints and the critical point(s).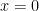 , then
, then  . On the other hand, if
. On the other hand, if  , then
, then  .
.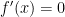 :
:![f'(x) = -\left( \displaystyle \frac{x^2}{m_1} + \frac{(1-x)^2}{m_2} \right)^{-2} \left[ \displaystyle \frac{2x}{m_1} - \frac{2(1-x)}{m_2} \right] = 0](https://s0.wp.com/latex.php?latex=f%27%28x%29+%3D+-%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7Bx%5E2%7D%7Bm_1%7D+%2B+%5Cfrac%7B%281-x%29%5E2%7D%7Bm_2%7D+%5Cright%29%5E%7B-2%7D+%5Cleft%5B+%5Cdisplaystyle+%5Cfrac%7B2x%7D%7Bm_1%7D+-+%5Cfrac%7B2%281-x%29%7D%7Bm_2%7D+%5Cright%5D+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002)

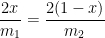
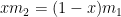



![f \left( \displaystyle \frac{m_1}{m_1+m_2} \right) = \left( \displaystyle \frac{1}{m_1} \frac{m_1^2}{(m_1+m_2)^2} + \frac{1}{m_2} \left[1-\frac{m_1}{m_1+m_2}\right]^2 \right)^{-1}](https://s0.wp.com/latex.php?latex=f+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7Bm_1%7D%7Bm_1%2Bm_2%7D+%5Cright%29+%3D+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bm_1%7D+%5Cfrac%7Bm_1%5E2%7D%7B%28m_1%2Bm_2%29%5E2%7D+%2B+%5Cfrac%7B1%7D%7Bm_2%7D+%5Cleft%5B1-%5Cfrac%7Bm_1%7D%7Bm_1%2Bm_2%7D%5Cright%5D%5E2+%5Cright%29%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![f \left( \displaystyle \frac{m_1}{m_1+m_2} \right) = \left( \displaystyle \frac{1}{m_1} \frac{m_1^2}{(m_1+m_2)^2} + \frac{1}{m_2} \left[\frac{m_2}{m_1+m_2}\right]^2 \right)^{-1}](https://s0.wp.com/latex.php?latex=f+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7Bm_1%7D%7Bm_1%2Bm_2%7D+%5Cright%29+%3D+%5Cleft%28+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bm_1%7D+%5Cfrac%7Bm_1%5E2%7D%7B%28m_1%2Bm_2%29%5E2%7D+%2B+%5Cfrac%7B1%7D%7Bm_2%7D+%5Cleft%5B%5Cfrac%7Bm_2%7D%7Bm_1%2Bm_2%7D%5Cright%5D%5E2+%5Cright%29%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002)



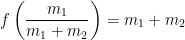
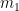 and
and  , while the absolute maximum is equal to
, while the absolute maximum is equal to  .
.
 is much smaller than
is much smaller than 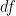 will be close to
will be close to  .
. ), then
), then  , but no larger.
, but no larger.
 . A valid answer gets 4 points; the smallest answer in the class will get 5 points.” It was basically free extra credit… any positive number would work, but it was a (hopefully) fun way for students to be a little competitive in coming up with small positive numbers, which is the intuitive meaning of
. A valid answer gets 4 points; the smallest answer in the class will get 5 points.” It was basically free extra credit… any positive number would work, but it was a (hopefully) fun way for students to be a little competitive in coming up with small positive numbers, which is the intuitive meaning of  or
or  . Except for one particularly gutsy student who wrote, “The probability that Dr. Q gets a date on Friday night.” For sheer nerve, he got the 5 points that year.
. Except for one particularly gutsy student who wrote, “The probability that Dr. Q gets a date on Friday night.” For sheer nerve, he got the 5 points that year. .” That was especially clever from a calculus student, as that’s the essence of a fairly common technique when writing proofs in real analysis.
.” That was especially clever from a calculus student, as that’s the essence of a fairly common technique when writing proofs in real analysis.
