From the category “I Can’t Believe What I Just Read,” the following question was posed to a question-and-answer statistics board last month:
Suppose we have data set
with
points. We want to perform a linear regression, but first we sort the
values and the
values independently of each other, forming data set
. Is there any meaningful interpretation of the regression on the new data set? Does this have a name?
I imagine this is a silly question so I apologize, I’m not formally trained in stats. In my mind this completely destroys our data and the regression is meaningless. But my manager says he gets “better regressions most of the time” when he does this (here “better” means more predictive). I have a feeling he is deceiving himself.
The answers were priceless:
Your intuition is correct: the independently sorted data have no reliable meaning because the inputs and outputs are being randomly mapped to one another rather than what the observed relationship was.
There is a (good) chance that the regression on the sorted data will look nice, but it is meaningless in context.
And:
If you want to convince your boss, you can show what is happening with simulated, random, independent x,y data. With R:
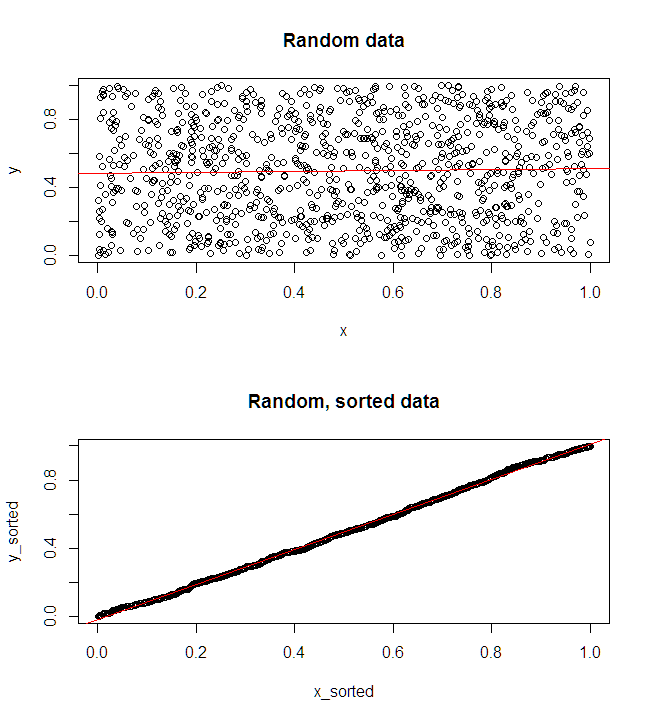
And:
This technique is actually amazing. I’m finding all sorts of relationships that I never suspected. For instance, I would have not have suspected that the numbers that show up in Powerball lottery, which it is CLAIMED are random, actually are highly correlated with the opening price of Apple stock on the same day! Folks, I think we’re about to cash in big time. 🙂
The sad end of the story, from the original poster:
Thank you for all of your nice and patient examples. I showed him the examples by @RUser4512 and @gung and he remains staunch. He’s becoming irritated and I’m becoming exhausted. I feel crestfallen. I want my work to mean something. I will probably begin looking for other jobs soon.

I just wonder what other horrors are in use in “big data analysis”?