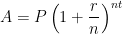The following problem appeared in Volume 53, Issue 4 (2022) of The College Mathematics Journal.
Define, for every non-negative integer
, the
.
Consider the sequence of complex polynomials in
defined by
for every non-negative integer
, where
. It is clear that
has degree
and thus has the representation
,
where each
is a positive integer. Prove that
for
.
This problem appeared in the same issue as the probability problem considered in the previous two posts. Looking back, I think that the confidence that I gained by solving that problem gave me the persistence to solve this problem as well.
My first thought when reading this problem was something like “This involves sums, polynomials, and binomial coefficients. And since the sequence is recursively defined, it’s probably going to involve a proof by mathematical induction. I can do this.”
My second thought was to use Mathematica to develop my own intuition and to confirm that the claimed pattern actually worked for the first few values of

As claimed in the statement of the problem, each 



and the problem claims that the coefficient of

Confident that the pattern actually worked, all that remained was pushing through the proof by induction.
We proceed by induction on 

Although not necessary, I’ll add for good measure that

and



This next calculation illustrates what’s coming later. In the previous calculation, the coefficient of 

This is accomplished by examining all pairs, one from the left product and one from the right product, so that the exponent works out to be

For the inductive step, we assume that, for some 

Our goal is to show that 

For 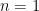


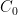
For 












The last step used a recursive relationship for the Catalan numbers that I vaguely recalled but absolutely had to look up to complete the proof.

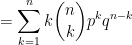
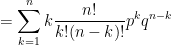

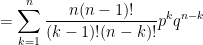





 .
. is a positive integer, then
is a positive integer, then  is a multiple of 4.
is a multiple of 4.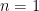 :
:  , which is clearly a multiple of 4.
, which is clearly a multiple of 4.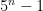 is a multiple of 4, then
is a multiple of 4, then  . (Groans and laughter.) It’s good to be the king.
. (Groans and laughter.) It’s good to be the king. , where
, where 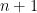 . We wish to show that
. We wish to show that 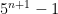 is also a multiple of 4.
is also a multiple of 4.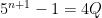 , where
, where 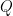 is some (possibly different) integer.
is some (possibly different) integer.

 by the induction hypothesis
by the induction hypothesis
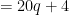
 .
. , then
, then  ,
, is the number of successes in
is the number of successes in  represents the probability of success on any one trial, and (to my shame)
represents the probability of success on any one trial, and (to my shame)  . We write down
. We write down
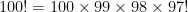 , and cancel.
, and cancel. is a factor of
is a factor of  .”
.” ?” Yes, I’m sure.
?” Yes, I’m sure. .
.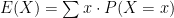

![\hbox{SD}(X) = \sqrt{ E(X^2) - [E(X)]^2 }](https://s0.wp.com/latex.php?latex=%5Chbox%7BSD%7D%28X%29+%3D+%5Csqrt%7B+E%28X%5E2%29+-+%5BE%28X%29%5D%5E2+%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 and
and  ,
,

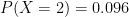
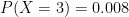
 and
and  . We had just done this the previous class period; however, I know full well that they haven’t yet committed those formulas to memory. So here’s the one-liner that I use: “If you had a good professor, you’d remember how to do this.”
. We had just done this the previous class period; however, I know full well that they haven’t yet committed those formulas to memory. So here’s the one-liner that I use: “If you had a good professor, you’d remember how to do this.”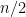 games. Suppose that the chance that Player X wins is
games. Suppose that the chance that Player X wins is  .
.
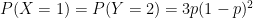


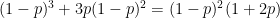 .
.


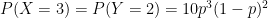
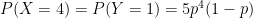

 .
. and
and  on the interval
on the interval 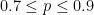 are shown below in blue and orange, respectively. The lesson is clear: if
are shown below in blue and orange, respectively. The lesson is clear: if  , then clearly the chance that Player Y wins is less than 50%. However, Player Y’s chances of upsetting Player X are greater if they play a best 2-out-of-3 series instead of a best 3-out-of-5 series.
, then clearly the chance that Player Y wins is less than 50%. However, Player Y’s chances of upsetting Player X are greater if they play a best 2-out-of-3 series instead of a best 3-out-of-5 series.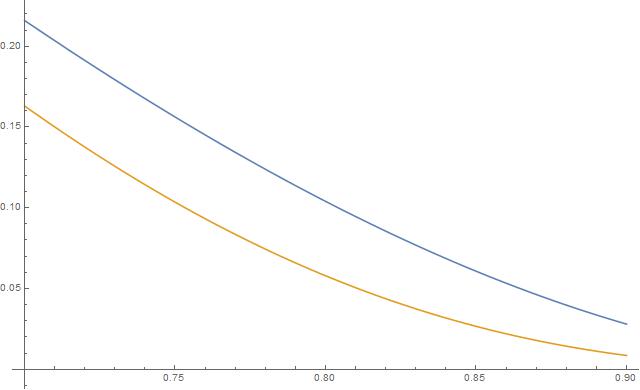
 .)
.)

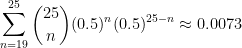 .
.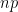 and
and 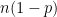 are also decently large).
are also decently large).
 and standard deviation
and standard deviation 
 axis can be adjusted. For example, if
axis can be adjusted. For example, if  and
and  , it doesn’t make much sense to show the full histogram; it suffices to have a maximum value around 5 or so.
, it doesn’t make much sense to show the full histogram; it suffices to have a maximum value around 5 or so. chance in
chance in 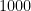 . What is the probability that, after playing
. What is the probability that, after playing 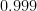 . Therefore, the chance of not winning
. Therefore, the chance of not winning  , which we can approximate with a calculator.
, which we can approximate with a calculator.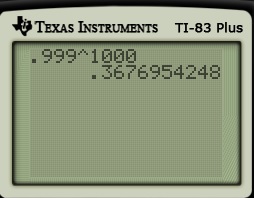

 ? Then the probability would be
? Then the probability would be  .
.
 , so that the probability of never winning for both problems is approximately
, so that the probability of never winning for both problems is approximately 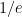 .
.
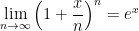
 , we find
, we find
 , we have
, we have![\ln \left[ \displaystyle \lim_{n \to \infty} \left(1 + \frac{x}{n}\right)^n \right] = \displaystyle \lim_{n \to \infty} \ln \left[ \left(1 + \frac{x}{n}\right)^n \right]](https://s0.wp.com/latex.php?latex=%5Cln+%5Cleft%5B+%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cleft%281+%2B+%5Cfrac%7Bx%7D%7Bn%7D%5Cright%29%5En+%5Cright%5D+%3D+%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cln+%5Cleft%5B+%5Cleft%281+%2B+%5Cfrac%7Bx%7D%7Bn%7D%5Cright%29%5En+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\ln \left[ \displaystyle \lim_{n \to \infty} \left(1 + \frac{x}{n}\right)^n \right] = \displaystyle \lim_{n \to \infty} n \ln \left(1 + \frac{x}{n}\right)](https://s0.wp.com/latex.php?latex=%5Cln+%5Cleft%5B+%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cleft%281+%2B+%5Cfrac%7Bx%7D%7Bn%7D%5Cright%29%5En+%5Cright%5D+%3D+%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+n+%5Cln+%5Cleft%281+%2B+%5Cfrac%7Bx%7D%7Bn%7D%5Cright%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\ln \left[ \displaystyle \lim_{n \to \infty} \left(1 + \frac{x}{n}\right)^n \right] = \displaystyle \lim_{n \to \infty} \frac{ \displaystyle \ln \left(1 + \frac{x}{n}\right)}{\displaystyle \frac{1}{n}}](https://s0.wp.com/latex.php?latex=%5Cln+%5Cleft%5B+%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cleft%281+%2B+%5Cfrac%7Bx%7D%7Bn%7D%5Cright%29%5En+%5Cright%5D+%3D+%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cfrac%7B+%5Cdisplaystyle+%5Cln+%5Cleft%281+%2B+%5Cfrac%7Bx%7D%7Bn%7D%5Cright%29%7D%7B%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bn%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 as
as 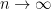 , and so we may use L’Hopital’s rule, differentiating both the numerator and the denominator with respect to
, and so we may use L’Hopital’s rule, differentiating both the numerator and the denominator with respect to ![\ln \left[ \displaystyle \lim_{n \to \infty} \left(1 + \frac{x}{n}\right)^n \right] = \displaystyle \lim_{n \to \infty} \frac{ \displaystyle \frac{1}{1 + \frac{x}{n}} \cdot \frac{-x}{n^2} }{\displaystyle \frac{-1}{n^2}}](https://s0.wp.com/latex.php?latex=%5Cln+%5Cleft%5B+%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cleft%281+%2B+%5Cfrac%7Bx%7D%7Bn%7D%5Cright%29%5En+%5Cright%5D+%3D+%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cfrac%7B+%5Cdisplaystyle+%5Cfrac%7B1%7D%7B1+%2B+%5Cfrac%7Bx%7D%7Bn%7D%7D+%5Ccdot+%5Cfrac%7B-x%7D%7Bn%5E2%7D+%7D%7B%5Cdisplaystyle+%5Cfrac%7B-1%7D%7Bn%5E2%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\ln \left[ \displaystyle \lim_{n \to \infty} \left(1 + \frac{x}{n}\right)^n \right] = \displaystyle \lim_{n \to \infty} \displaystyle \frac{x}{1 + \frac{x}{n}}](https://s0.wp.com/latex.php?latex=%5Cln+%5Cleft%5B+%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cleft%281+%2B+%5Cfrac%7Bx%7D%7Bn%7D%5Cright%29%5En+%5Cright%5D+%3D+%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cdisplaystyle+%5Cfrac%7Bx%7D%7B1+%2B+%5Cfrac%7Bx%7D%7Bn%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\ln \left[ \displaystyle \lim_{n \to \infty} \left(1 + \frac{x}{n}\right)^n \right] = \displaystyle \frac{x}{1 + 0}](https://s0.wp.com/latex.php?latex=%5Cln+%5Cleft%5B+%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cleft%281+%2B+%5Cfrac%7Bx%7D%7Bn%7D%5Cright%29%5En+%5Cright%5D+%3D+%5Cdisplaystyle+%5Cfrac%7Bx%7D%7B1+%2B+0%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\ln \left[ \displaystyle \lim_{n \to \infty} \left(1 + \frac{x}{n}\right)^n \right] = x](https://s0.wp.com/latex.php?latex=%5Cln+%5Cleft%5B+%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cleft%281+%2B+%5Cfrac%7Bx%7D%7Bn%7D%5Cright%29%5En+%5Cright%5D+%3D+x&bg=ffffff&fg=000000&s=0&c=20201002)
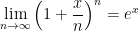
 can be derived from the formula for discrete compound interest
can be derived from the formula for discrete compound interest