In the past couple of months, I read a couple of very sobering and depressing articles on how hard it is for talented undergraduates to be admitted into graduate school in 2026. From MAA (Mathematical Association of America) FOCUS:
Hannah’s professors kept telling her she was a shoo-in for grad school. With a published paper in symplectic geometry, another one in combinatorial game theory in the works, and a 4.0 GPA in her math classes, she was a star in her department at Rhodes College. So, when she applied to a dozen PhD programs in math with the strong support of her department, she expected to have some exciting options to weigh as acceptances rolled in. Right on schedule, her first encouraging sign came from a state school in the North. They flew her up to campus to entice her to join their program, and they offered her a nice research assistantship—but with a caveat: funding could only be guaranteed for one year. The offer sounded promising, but only one year of committed funding? That feels odd.
Not long after her campus visit, she heard back from the University of Kentucky. That’s when she really started to sense something was off. According to Hannah, Kentucky told
her, “We are currently waiting to see how things play out. You are one of the top students that we want to admit… if we can admit any students at all. Please stand by.” Her mentors validated that this was unusual, but they were confident nonetheless that more acceptances were on the way. As the April 15 deadline for students to accept offers of admission approached, Hannah heard from another school that she was on the waitlist and a couple more that she would not be receiving an offer. Oddly, she also got an Instagram message from a grad student at one of the schools she applied to. The
grad student told her, in effect, that one of the professors who was reviewing her application was so taken with her research that they were telling the other faculty and students about it. This excitement about her work gave her hope that another
offer was on the horizon—but none materialized.
And from another article from Physics Today (American Institute of Physics):
“Strange and harrowing.” That’s how Sara Earnest describes the process of applying for physics PhD programs this year. She graduated in May from Johns Hopkins University with two and a half years of undergraduate research experience. But just two weeks shy of the 15 April national deadline for prospective students to commit to graduate programs, she had been wait-listed by one, rejected by seven, and was still waiting to hear from three.
In the end, Earnest didn’t get into any of them. She plans to try again next year.
Beyond the anecdotes, the articles suggest a number of factors that have made getting into graduate school in STEM significantly harder than in past years:
- Improved stipends from graduate students without additional funding from universities necessarily causes reduced cohorts.
- The threat (real and perceived) of decreased federal support for STEM research: the effects on highly selective programs have a trickle-down effect on other grad programs.
- After-effects of COVID and inflation.

 and
and 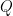 are chosen at random (uniformly) from the interior of a unit circle. What is the probability that the circle whose diameter is segment
are chosen at random (uniformly) from the interior of a unit circle. What is the probability that the circle whose diameter is segment  lies entirely in the interior of the unit circle?
lies entirely in the interior of the unit circle? be the interior of the circle centered at the origin
be the interior of the circle centered at the origin  with radius
with radius  . Also, let
. Also, let  denote the circle with diameter
denote the circle with diameter 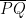 , and let
, and let  be the distance of
be the distance of  .
. , I will integrate over this conditional probability:
, I will integrate over this conditional probability: ,
, is the cumulative distribution function of
is the cumulative distribution function of  . For
. For  ,
, .
. .
. . Then the endpoints
. Then the endpoints  and
and  become
become  and
and  . Also,
. Also,  . Therefore,
. Therefore, 


![= \displaystyle \frac{2}{3} \left[ u^{3/2} \right]_0^1](https://s0.wp.com/latex.php?latex=%3D+%5Cdisplaystyle+%5Cfrac%7B2%7D%7B3%7D+%5Cleft%5B++u%5E%7B3%2F2%7D+%5Cright%5D_0%5E1&bg=ffffff&fg=000000&s=0&c=20201002)
![=\displaystyle \frac{2}{3}\left[ (1)^{3/2} - (0)^{3/2} \right]](https://s0.wp.com/latex.php?latex=%3D%5Cdisplaystyle++%5Cfrac%7B2%7D%7B3%7D%5Cleft%5B+%281%29%5E%7B3%2F2%7D+-+%280%29%5E%7B3%2F2%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 ,
,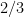 . Naturally, simulation is not a proof, and so I started thinking about how to prove this.
. Naturally, simulation is not a proof, and so I started thinking about how to prove this. from the origin. What is the probability that the point
from the origin. What is the probability that the point  . In this way, the probability in question is ultimately going to be a function of
. In this way, the probability in question is ultimately going to be a function of 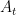 be the set of all points
be the set of all points  , the probability of desired property happening is
, the probability of desired property happening is .
. and a semiminor axis of length
and a semiminor axis of length  . Now I had to think about how to prove this.
. Now I had to think about how to prove this. , where
, where  is the midpoint of
is the midpoint of  . Then the coordinates of
. Then the coordinates of  ,
,
 .
. ,
,![\displaystyle \sqrt{ \frac{1}{4} \left[ (x+t)^2 + y^2 \right]} + \sqrt{ \frac{1}{4} \left[ (x-t)^2 + y^2 \right]} < 1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csqrt%7B+%5Cfrac%7B1%7D%7B4%7D+%5Cleft%5B+%28x%2Bt%29%5E2+%2B+y%5E2+%5Cright%5D%7D+%2B+%5Csqrt%7B+%5Cfrac%7B1%7D%7B4%7D+%5Cleft%5B+%28x-t%29%5E2+%2B+y%5E2+%5Cright%5D%7D+%3C+1&bg=ffffff&fg=000000&s=0&c=20201002)

 .
.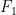 and
and 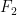 , called the foci, an ellipse is defined to be the set of all points
, called the foci, an ellipse is defined to be the set of all points  , where
, where  is a constant. If the coordinates of
is a constant. If the coordinates of  , and
, and  , then this becomes
, then this becomes .
.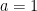 and
and  . Furthermore,
. Furthermore,  .
. .
. .
.
 .
.
 ; as it turned out, it looked like the semiminor axis now had a length of
; as it turned out, it looked like the semiminor axis now had a length of 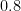 .
.
 is a Pythagorean triple, meaning that
is a Pythagorean triple, meaning that 



 , a very familiar number from trigonometry:
, a very familiar number from trigonometry:
 .
.
 and
and 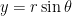 , where the distance from the origin
, where the distance from the origin  is chosen at random from
is chosen at random from  . Unfortunately, this simple simulation generates too many points that are close to the origin and not enough that are close to the circle:
. Unfortunately, this simple simulation generates too many points that are close to the origin and not enough that are close to the circle:
 is the same as saying that the point lies inside the circle centered at the origin with radius
is the same as saying that the point lies inside the circle centered at the origin with radius  .
.![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , so that
, so that  . All this to say, the above simulation did not produce points uniformly chosen from the unit circle.
. All this to say, the above simulation did not produce points uniformly chosen from the unit circle. . In other words, we will chose randomly chosen radius to have the form
. In other words, we will chose randomly chosen radius to have the form  , where
, where  is chosen uniformly on
is chosen uniformly on  ,
, 
