In my capstone class for future secondary math teachers, I ask my students to come up with ideas for engaging their students with different topics in the secondary mathematics curriculum. In other words, the point of the assignment was not to devise a full-blown lesson plan on this topic. Instead, I asked my students to think about three different ways of getting their students interested in the topic in the first place.
I plan to share some of the best of these ideas on this blog (after asking my students’ permission, of course).
This student submission again comes from my former student Caitlin Kirk. Her topic: how to engage Algebra II or Precalculus students when solving logarithmic equations.

B. Curriculum: How does this topic extend what your students should have learned in previous courses?
Logarithms are a topic that appears at multiple levels of high school math. In Algebra II, students are first introduced to logarithms when they are asked to identify graphs of parent functions including f (x) = logax. Later in the same class, they learn to formulate equations and inequalities based on logarithmic functions by exploring the relationship between logarithms and their inverses. From there, they can develop a definition of a logarithm.
Solving logarithmic equations extends what students learned about logarithms in Algebra II. Once a proper definition of logarithms has been established, along with a graphical foundation of logs, students learn to solve logarithmic equations. Properties of logarithms are used to expand, condense, and solve logarithms without a calculator in Pre Calculus. Practical applications of the logarithmic equation also follow from previous skills. Students learn to calculate the pH of a solution, decibel voltage gain, intensity of earthquakes measure on the Richter scale, depreciation, and the apparent loudness of sound using logarithms.
C. Culture: How has this topic appeared in the news?
One application of logarithmic equations is calculating the intensity of earthquakes measured on the Richter scale using the following equation:

where 

Reports of earthquake activity appear in the news often and are always accompanied by a measurement from the Richter scale. One such report can be found here: http://www.bbc.co.uk/news/world-asia-20638696. As the story says, a 7.3 magnitude earthquake struck off the coast of Japan in December of 2012, and created a small tsunami. There were six aftershocks of this quake whose Richter scale measurements are also given. The article also explains how Japan has been able to enact an early warning system that predicts the intensity of an earthquake before it causes damage. All of the calculations given in this story, and almost all others involving earthquakes, involves the use of the Richter scale logarithmic equation.
D. History: What are the contributions of various cultures to this topic?
The development of logarithms saw contributions from several different countries beginning with the Babylonians (2000-1600 BC) who developed the first known mathematical tables. They also introduced square multiplication in which they simply but accurately multiplied two numbers using only addition and subtraction. Michael Stifel, of Germany, was the first mathematician to use an exponent in 1544. He developed an early version of the logarithmic table containing integers and powers of 2. Perhaps the most important contribution to logarithms came from John Napier in Scotland in 1619. He, like the Babylonians, was working with on breaking multiplication, division, and root extraction down to only addition and subtraction. Therefore, he created the “logarithm” 

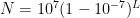
for which he wrote 
Napier’s definition of the logarithm led to the following logarithmic identities that are still taught today:
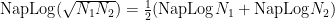
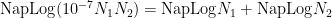

Henry Briggs, in England, published his work on logarithms in 1624, which included logarithms of 30,000 natural numbers to the 14th decimal place worked by hand! Shortly after, back in Germany, Johannes Kepler used a logarithmic scale on a Cartesian plane to create a linear graph the elliptical shape of the cosmos. In 1632, in Italy, Bonaventura Cavalieri published extensive tables of logarithms including the logs of trig functions (excluding cosine). Finally, Leonhard Euler made one of the most commonly known contributions to logarithms by making the number 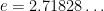


Logarithms were developed as a result of the contributions of many cultures spanning Europe and beyond, dating back over 4000 years.
 and
and  . Of course, he knew that these rules were true and he could apply them in complex problems, but he didn’t know why they were true. And he wanted to have this deeper knowledge of mathematics beyond the ability to solve routine algebra problems.
. Of course, he knew that these rules were true and he could apply them in complex problems, but he didn’t know why they were true. And he wanted to have this deeper knowledge of mathematics beyond the ability to solve routine algebra problems.
 and
and  , this can be proven by repeated multiplication:
, this can be proven by repeated multiplication: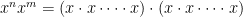 repeated
repeated  repeated
repeated 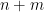 times
times and
and 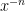 should be defined so that this rule still holds even if one (or both) of
should be defined so that this rule still holds even if one (or both) of 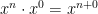



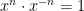
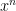 for positive integers
for positive integers  :
:



 with each step up, while an extra
with each step up, while an extra  .
.

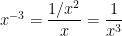
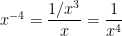
 is negative, that
is negative, that  does not fit the
does not fit the 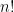 . Recall that, for positive integers, we have
. Recall that, for positive integers, we have




 that may or may not be as convincing as the first explanation. Let’s count the number of “words” that can made using each of the three letters A, B, and C exactly once. Ignoring that most of these don’t appear in the dictionary, there are six possible words:
that may or may not be as convincing as the first explanation. Let’s count the number of “words” that can made using each of the three letters A, B, and C exactly once. Ignoring that most of these don’t appear in the dictionary, there are six possible words: different words using four letters,
different words using four letters,  different words using three letters, and
different words using three letters, and  different words using two letters.
different words using two letters. different possible choices for the first letter in the word. Next, the second letter can be anything but the first letter, so there are
different possible choices for the first letter in the word. Next, the second letter can be anything but the first letter, so there are  different possibilities for the second letter. Then there are
different possibilities for the second letter. Then there are  remaining possibilities for the third letter, leaving
remaining possibilities for the third letter, leaving  , or
, or 
 for all complex numbers
for all complex numbers  ,
, 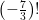 and even
and even 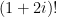 . I’ll probably discuss this in a future post.
. I’ll probably discuss this in a future post. . To get
. To get 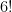 , we multiply the top line by
, we multiply the top line by 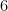 :
: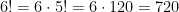 .
.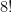 .” Then I planted a firm facepalm for having factorials as my first reaction. (Perhaps not surprisingly, I was still single when this happened.)
.” Then I planted a firm facepalm for having factorials as my first reaction. (Perhaps not surprisingly, I was still single when this happened.) divided by
divided by  .
.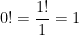 .
. .
.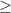 Height restriction)
Height restriction) 160 cm) The world’s largest hockey stick and puck are in Duncan, British Columbia. The stick is over 62 m in length and weighs almost 28,000 kg. Is your equipment legal?
160 cm) The world’s largest hockey stick and puck are in Duncan, British Columbia. The stick is over 62 m in length and weighs almost 28,000 kg. Is your equipment legal?
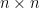 matrix
matrix 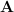 has an inverse:
has an inverse:
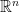
 has a unique solution
has a unique solution
 is the trivial solution
is the trivial solution 
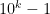 . I asked my students how I’d write out
. I asked my students how I’d write out 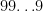 , a numeral with
, a numeral with  consecutive
consecutive  s. So I said, “Who let the dogs out? Me. See:
s. So I said, “Who let the dogs out? Me. See: 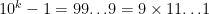 , which is clearly a multiple of 9.
, which is clearly a multiple of 9.
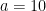 and
and 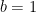 .
.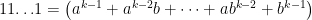 ?
?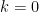 , then
, then 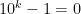 , which is a multiple of 9.
, which is a multiple of 9. is a multiple of 9, we observe that
is a multiple of 9, we observe that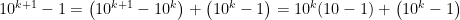 ,
,
 , apparently targeted toward mathematicians.
, apparently targeted toward mathematicians.