In honor of Pi Day, here’s a bonus edition of Mean Green Math from two years ago.
March 14, 2015 has been labeled the Pi Day of the Century because of the way this day is abbreviated, at least in America: 3/14/15.
I was recently asked an interesting question: did any of our ancestors observe Pi Day about 400 years ago on 3/14/1592? The answer is, I highly doubt it.
My first thought was that $latex pi$ may not have been known to that many decimal places in 1592. However, a quick check on Wikipedia (see also here), as well as the book “$latex pi$ Unleashed,” verifies that my initial thought was wrong. In China, 7 places of accuracy were obtained by the 5th century. By the 14th century, $latex pi$ was known to 13 decimal places in India. In the 15th century, $latex pi$ was calculated to 16 decimal places in Persia.
It’s highly doubtful that the mathematicians in these ancient cultures actually talked to…
View original post 265 more words
 typically exhibits exponential growth (if
typically exhibits exponential growth (if 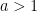 ) or exponential decay (if
) or exponential decay (if  ). The one exception is if
). The one exception is if 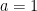 , when the function is merely a constant. Which often leads to my favorite blooper from Star Trek. The crew is trying to find a stowaway, and they get the bright idea of turning off all the sound on the ship and then turning up the sound so that the stowaway’s heartbeat can be heard. After all, Captain Kirk boasts, the Enterprise has the ability to amplify sound by 1 to the fourth power.
, when the function is merely a constant. Which often leads to my favorite blooper from Star Trek. The crew is trying to find a stowaway, and they get the bright idea of turning off all the sound on the ship and then turning up the sound so that the stowaway’s heartbeat can be heard. After all, Captain Kirk boasts, the Enterprise has the ability to amplify sound by 1 to the fourth power. or
or  naturally appears. Sometimes, it’s an angle in a triangle or a displacement when graphing a sinusoidal function. Other times, it represents the cumulative distribution function of a standard normal distribution.
naturally appears. Sometimes, it’s an angle in a triangle or a displacement when graphing a sinusoidal function. Other times, it represents the cumulative distribution function of a standard normal distribution. symbol.
symbol. :
: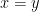
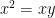






 , is rejecting the null hypothesis even though the null hypothesis is true. Conversely, a Type II error, whose probability is denoted by
, is rejecting the null hypothesis even though the null hypothesis is true. Conversely, a Type II error, whose probability is denoted by  , is retaining the null hypothesis even though the null hypothesis is false.
, is retaining the null hypothesis even though the null hypothesis is false. and
and  , so there’s no chance of making a mistake. I’ll tell my students:
, so there’s no chance of making a mistake. I’ll tell my students:
 ,
, .
. ,
, be an integer. Then
be an integer. Then 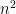 is odd.” I’ll ask my students, “What is the structure of this proof?”
is odd.” I’ll ask my students, “What is the structure of this proof?” with real coefficients has a complex root
with real coefficients has a complex root  , then
, then 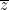 is also a root. It’s a blue-light special: two for the price of one.
is also a root. It’s a blue-light special: two for the price of one.