Numerical integration is a standard topic in first-semester calculus. From time to time, I have received questions from students on various aspects of this topic, including:
- Why is numerical integration necessary in the first place?
- Where do these formulas come from (especially Simpson’s Rule)?
- How can I do all of these formulas quickly?
- Is there a reason why the Midpoint Rule is better than the Trapezoid Rule?
- Is there a reason why both the Midpoint Rule and the Trapezoid Rule converge quadratically?
- Is there a reason why Simpson’s Rule converges like the fourth power of the number of subintervals?
In this series, I hope to answer these questions. While these are standard questions in a introductory college course in numerical analysis, and full and rigorous proofs can be found on Wikipedia and Mathworld, I will approach these questions from the point of view of a bright student who is currently enrolled in calculus and hasn’t yet taken real analysis or numerical analysis.

In this post, we will perform an error analysis for the right-endpoint rule
![\int_a^b f(x) \, dx \approx h \left[f(x_1) + f(x_2) + \dots + f(x_n) \right] \equiv R_n](https://s0.wp.com/latex.php?latex=%5Cint_a%5Eb+f%28x%29+%5C%2C+dx+%5Capprox+h+%5Cleft%5Bf%28x_1%29+%2B+f%28x_2%29+%2B+%5Cdots+%2B+f%28x_n%29+%5Cright%5D+%5Cequiv+R_n&bg=ffffff&fg=000000&s=0&c=20201002)
where 



As noted above, a true exploration of error analysis requires the generalized mean-value theorem, which perhaps a bit much for a talented high school student learning about this technique for the first time. That said, the ideas behind the proof are accessible to high school students, using only ideas from the secondary curriculum, if we restrict our attention to the special case 

For this special case, the true area under the curve $f(x) = x^k$ on the subinterval ![[x_i, x_i +h]](https://s0.wp.com/latex.php?latex=%5Bx_i%2C+x_i+%2Bh%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \int_{x_i}^{x_i+h} x^k \, dx = \frac{1}{k+1} \left[ (x_i+h)^{k+1} - x_i^{k+1} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cint_%7Bx_i%7D%5E%7Bx_i%2Bh%7D+x%5Ek+%5C%2C+dx+%3D+%5Cfrac%7B1%7D%7Bk%2B1%7D+%5Cleft%5B+%28x_i%2Bh%29%5E%7Bk%2B1%7D+-+x_i%5E%7Bk%2B1%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![= \displaystyle \frac{1}{k+1} \left[x_i^{k+1} + {k+1 \choose 1} x_i^k h + {k+1 \choose 2} x_i^{k-1} h^2 + O(h^3) - x_i^{k+1} \right]](https://s0.wp.com/latex.php?latex=%3D+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bk%2B1%7D+%5Cleft%5Bx_i%5E%7Bk%2B1%7D+%2B+%7Bk%2B1+%5Cchoose+1%7D+x_i%5Ek+h+%2B+%7Bk%2B1+%5Cchoose+2%7D+x_i%5E%7Bk-1%7D+h%5E2+%2B+O%28h%5E3%29+-+x_i%5E%7Bk%2B1%7D+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![= \displaystyle \frac{1}{k+1} \left[ (k+1) x_i^k h + \frac{(k+1)k}{2} x_i^{k-1} h^2 + O(h^3) \right]](https://s0.wp.com/latex.php?latex=%3D+%5Cdisplaystyle+%5Cfrac%7B1%7D%7Bk%2B1%7D+%5Cleft%5B+%28k%2B1%29+x_i%5Ek+h+%2B+%5Cfrac%7B%28k%2B1%29k%7D%7B2%7D+x_i%5E%7Bk-1%7D+h%5E2+%2B+O%28h%5E3%29+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)

In the above, the shorthand 
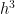


Using only the right-endpoint of the subinterval, the left-endpoint approximation of 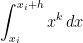
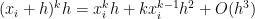
Subtracting, the error in this approximation will be equal to

Repeating the logic from the previous post in this series, this local error on ![[x_i, x_i+h]](https://s0.wp.com/latex.php?latex=%5Bx_i%2C+x_i%2Bh%5D&bg=ffffff&fg=000000&s=0&c=20201002)

![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=000000&s=0&c=20201002)

One thought on “Thoughts on Numerical Integration (Part 14): Right endpoint rule and local rate of convergence”