Numerical integration is a standard topic in first-semester calculus. From time to time, I have received questions from students on various aspects of this topic, including:
- Why is numerical integration necessary in the first place?
- Where do these formulas come from (especially Simpson’s Rule)?
- How can I do all of these formulas quickly?
- Is there a reason why the Midpoint Rule is better than the Trapezoid Rule?
- Is there a reason why both the Midpoint Rule and the Trapezoid Rule converge quadratically?
- Is there a reason why Simpson’s Rule converges like the fourth power of the number of subintervals?
In this series, I hope to answer these questions. While these are standard questions in a introductory college course in numerical analysis, and full and rigorous proofs can be found on Wikipedia and Mathworld, I will approach these questions from the point of view of a bright student who is currently enrolled in calculus and hasn’t yet taken real analysis or numerical analysis.

In the previous post in this series, I discussed three different ways of numerically approximating the definite integral 

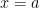
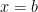

In this series, we’ll choose equal-sized subintervals of the interval ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=000000&s=0&c=20201002)


![\int_a^b f(x) \, dx \approx h \left[f(x_0) + f(x_1) + \dots + f(x_{n-1}) \right] \equiv L_n](https://s0.wp.com/latex.php?latex=%5Cint_a%5Eb+f%28x%29+%5C%2C+dx+%5Capprox+h+%5Cleft%5Bf%28x_0%29+%2B+f%28x_1%29+%2B+%5Cdots+%2B+f%28x_%7Bn-1%7D%29+%5Cright%5D+%5Cequiv+L_n&bg=ffffff&fg=000000&s=0&c=20201002)
using left endpoints,
![\int_a^b f(x) \, dx \approx h \left[f(x_1) + f(x_2) + \dots + f(x_n) \right] \equiv R_n](https://s0.wp.com/latex.php?latex=%5Cint_a%5Eb+f%28x%29+%5C%2C+dx+%5Capprox+h+%5Cleft%5Bf%28x_1%29+%2B+f%28x_2%29+%2B+%5Cdots+%2B+f%28x_n%29+%5Cright%5D+%5Cequiv+R_n&bg=ffffff&fg=000000&s=0&c=20201002)
using right endpoints, and
![\int_a^b f(x) \, dx \approx h \left[f(c_1) + f(c_2) + \dots + f(c_n) \right] \equiv M_n](https://s0.wp.com/latex.php?latex=%5Cint_a%5Eb+f%28x%29+%5C%2C+dx+%5Capprox+h+%5Cleft%5Bf%28c_1%29+%2B+f%28c_2%29+%2B+%5Cdots+%2B+f%28c_n%29+%5Cright%5D+%5Cequiv+M_n&bg=ffffff&fg=000000&s=0&c=20201002)
using the midpoints of the subintervals.
All three of these approximations were obtained by approximating the above shaded region by rectangles. However, perhaps it might be better to use some other shape besides rectangles. In the Trapezoidal Rule, we approximate the area by using (surprise!) trapezoids, as in the figure below.
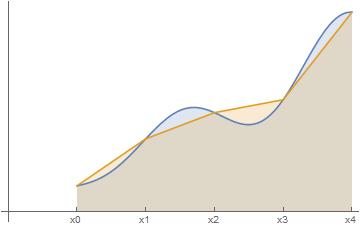
The first trapezoid has height 
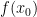
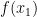
![\frac{1}{2} h[ f(x_0) + f(x_1) ]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D+h%5B+f%28x_0%29+%2B+f%28x_1%29+%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![T_n = \displaystyle \frac{h}{2}[f(x_0) + f(x_1)] + \frac{h}{2} [f(x_1) + f(x_2)] + \dots +](https://s0.wp.com/latex.php?latex=T_n+%3D+%5Cdisplaystyle+%5Cfrac%7Bh%7D%7B2%7D%5Bf%28x_0%29+%2B+f%28x_1%29%5D+%2B+%5Cfrac%7Bh%7D%7B2%7D+%5Bf%28x_1%29+%2B+f%28x_2%29%5D+%2B+%5Cdots+%2B+&bg=ffffff&fg=000000&s=0&c=20201002)
![+ \displaystyle \frac{h}{2} [f(x_{n-2})+f(x_{n-1})] + \frac{h}{2} [f(x_{n-1})+f(x_n)]](https://s0.wp.com/latex.php?latex=%2B+%5Cdisplaystyle+%5Cfrac%7Bh%7D%7B2%7D+%5Bf%28x_%7Bn-2%7D%29%2Bf%28x_%7Bn-1%7D%29%5D+%2B+%5Cfrac%7Bh%7D%7B2%7D+%5Bf%28x_%7Bn-1%7D%29%2Bf%28x_n%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![= \displaystyle \frac{h}{2} [f(x_0) + 2f(x_1) + 2f(x_2) + \dots + 2f(x_{n-2}) + 2f(x_{n-1}) + f(x_n)].](https://s0.wp.com/latex.php?latex=%3D+%5Cdisplaystyle+%5Cfrac%7Bh%7D%7B2%7D+%5Bf%28x_0%29+%2B+2f%28x_1%29+%2B+2f%28x_2%29+%2B+%5Cdots+%2B+2f%28x_%7Bn-2%7D%29+%2B+2f%28x_%7Bn-1%7D%29+%2B+f%28x_n%29%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
Interestingly, 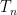

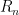

![= \displaystyle \frac{h}{2} \left[f(x_0) + f(x_1) + f(x_2) + \dots + f(x_{n-1}) \right]](https://s0.wp.com/latex.php?latex=%3D+%5Cdisplaystyle+%5Cfrac%7Bh%7D%7B2%7D+%5Cleft%5Bf%28x_0%29+%2B+f%28x_1%29+%2B+f%28x_2%29+%2B+%5Cdots+%2B+f%28x_%7Bn-1%7D%29+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![+\displaystyle \frac{h}{2} \left[f(x_1) + f(x_2) + \dots + f(x_{n-1}) + f(x_{n}) \right]](https://s0.wp.com/latex.php?latex=%2B%5Cdisplaystyle+%5Cfrac%7Bh%7D%7B2%7D+%5Cleft%5Bf%28x_1%29+%2B+f%28x_2%29+%2B+%5Cdots+%2B+f%28x_%7Bn-1%7D%29+%2B+f%28x_%7Bn%7D%29+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![= \displaystyle \frac{h}{2} \left[f(x_0) + 2f(x_1) + \dots + 2f(x_{n-1}) + f(x_n) \right]](https://s0.wp.com/latex.php?latex=%3D+%5Cdisplaystyle+%5Cfrac%7Bh%7D%7B2%7D+%5Cleft%5Bf%28x_0%29+%2B+2f%28x_1%29+%2B+%5Cdots+%2B+2f%28x_%7Bn-1%7D%29+%2B+f%28x_n%29+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)

Of course, as a matter of computation, it’s a lot quicker to directly compute

One thought on “Thoughts on Numerical Integration (Part 4): Derivation of Trapezoid Rule”