In my capstone class for future secondary math teachers, I ask my students to come up with ideas for engaging their students with different topics in the secondary mathematics curriculum. In other words, the point of the assignment was not to devise a full-blown lesson plan on this topic. Instead, I asked my students to think about three different ways of getting their students interested in the topic in the first place.
I plan to share some of the best of these ideas on this blog (after asking my students’ permission, of course).
This student submission comes from my former student Loc Nguyen. His topic, from Geometry: defining sine, cosine and tangent in a right triangle.

What interesting (i.e., uncontrived) word problems using this topic can your students do now?
There are many real world applications that involve in this topic and I will incorporate some problems in real life to engage the students. Suppose I have a classroom that has the shape of rectangular prism. I will begin my lesson by challenging the students to find the height of the classroom and of course I will award them with something cool. I believe this will ignite students’ curiosity and excitement to participate into the problem. In the process of finding the height, I will gradually introduce the concept of right triangle trigonometry. The students will learn the relationship of ratios of the sides in the triangle. Eventually, the students will realize that they need this concept for finding the height of the classroom. I will pose some guiding questions to drive them toward the solution. Such questions could be: what can I measure? Can we measure the angle from our eyes to the opposite corner of the ceiling point? What formula will help me to find the height?
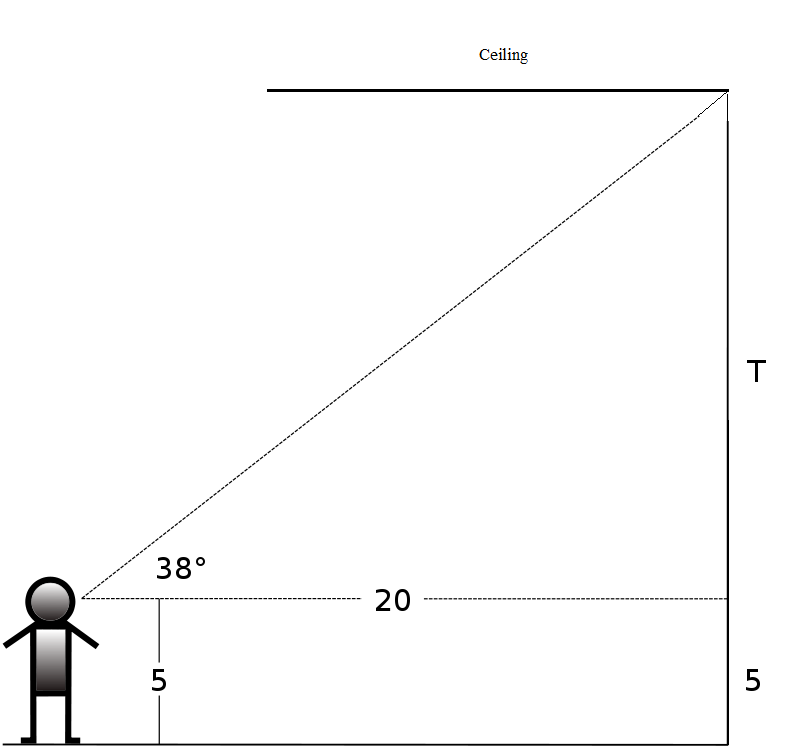
After this problem I will provide them many different real world problems to practice such as:


How can this topic be used in your students’ future courses in mathematics or science?
Knowing how to compute sine, cosine or tangent in the right triangle will help students a lot when they get to higher level math or other science class, especially Physics. In higher level math, students will always have the chance to encounter this concept. For example, in Pre-Calculus, the students will likely learn about polar system. This requires students to have the strong fundamental understandings of sine, cosine and tangent in a right triangle. Students will be asked to convert from the Cartesian system to polar system, or vice versa. If they do not grasp the ideas of this topic, they will eventually encounter huge obstacles in future. In science, especially physics, the students will learn a lot about the motions of an objects. This will involve concepts of force, velocity, speed, momentum. The students will need to understand the how to compute sine, cosine and tangent in the right triangle so that they can easily know how to approach the problems in physics.
How can technology (YouTube, Khan Academy [khanacademy.org], Vi Hart, Geometers Sketchpad, graphing calculators, etc.) be used to effectively engage students with this topic?
This website, https://www.geogebra.org/material/simple/id/48148 , can be a great tool for the students to understand the relationships of the sides in the right triangle. The website creates an activity for students to explore the ratios of the sides such as AC/BC, AC/AB, and BC/AB. The students will observe the changes of the ratios based on the changes of theta and side BC which is the hypotenuse. At this point, the students will be introduced the name of each side of the right triangle which corresponds to theta such as opposite, adjacent and hypotenuse. This activity allows the students to visualize what happens to the triangle when we change the angle or its side lengths. The students will then explore the activity to find interesting facts about the side ratios. I will pose some questions to help the students understand the relationships of side ratios. Such questions could be: What type of triangle is it? Tell me how the triangle changes as we change the hypotenuse or angle. If we know one side length and the angle, how can we find the other side lengths? Those questions allow me to introduce the terms sine, cosine, and tangent in the right triangle.

References
https://en.wikibooks.org/wiki/High_School_Trigonometry/Applications_of_Right_Triangle_Trigonometry
https://www.geogebra.org/material/simple/id/48148
